I'm currently using a scanning software "Drivve Image" to extract certain information from each paper. This software enables certain Regex code to be run if needed. It seems to be run with the UltraEdit Regex Engine.
I get the following scanned result:
1. 21Sid1
2. Ordernr
3. E17222
4. By
5. Seller
I need to search the string for the text Ordernr and then pick the following line E17222 which in the end will be said filename of the scanned document. I will never know the exact position of these two values in the string. That is why I need to focus on Ordernr because the text I need will always follow as the next line.
My requirements are such that I need the E17222 to be the only thing in the match result for this to work. I am only allowed to type plain regular expressions.
There is a great thread already: Regex to get the words after matching string
I've tested " \bOrdernr\s+\K\S+ "which works great..
Had it not been that the software don't allow for /K to be used. Are there any other ways of implementing \K?
Continuation
Though If the sample text involves a character behind "Ordernr" the current answer doesn't work to the extent I need. Like this sample:
21Sid1
Ordernr 1
E17222
By
Seller
The current solution picks up "1" and not the "next line" which would be "E17222". in the matched group. Needed to point that out for further involvement on the issue.
ordernr[\r\n]+([^\r\n]+)
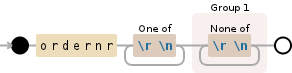
This regular expression will do the following:
ordernr substringordernr capture group 1Live Demo
https://regex101.com/r/dQ0gR6/1
Sample text
1. 21Sid1
2. Ordernr
3. E17222
4. By
5. Seller
Sample Matches
[0][0] = Ordernr
3. E17222
[0][1] = 3. E17222
NODE EXPLANATION
----------------------------------------------------------------------
ordernr 'ordernr'
----------------------------------------------------------------------
[\r\n]+ any character of: '\r' (carriage return),
'\n' (newline) (1 or more times (matching
the most amount possible))
----------------------------------------------------------------------
( group and capture to \1:
----------------------------------------------------------------------
[^\r\n]+ any character except: '\r' (carriage
return), '\n' (newline) (1 or more times
(matching the most amount possible))
----------------------------------------------------------------------
) end of \1
----------------------------------------------------------------------
To just capture the line using a look-around so that ordernr is not included in capture group 0 and to accommodate all the variation of \r and \n
(?<=ordernr\r|ordernr\n|ordernr\r\n)[^\r\n]+
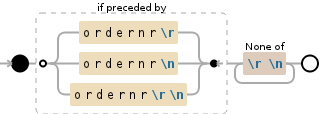
Live Demo
https://regex101.com/r/pA4fD4/2
Did some googling and from what I can grasp, the last parameter to the REGEXP.MATCH is the capture group to use. That means that you could use you own regex, without the \K, and just add a capture group to the number you want to extract.
\bOrdernr\s+(\S+)
This means that the number ends up in capture group 1 (the whole match is in 0 which I assume you've used).
The documentation isn't crystal clear, but I guess the syntax is
REGEXP.MATCH(<ZoneName>, "REGEX", CaptureGroup)
meaning you should use
REGEXP.MATCH(<ZoneName>, "\bOrdernr\s+(\S+)", 1)
There's a fair amount of guessing here though... ;)
If you love us? You can donate to us via Paypal or buy me a coffee so we can maintain and grow! Thank you!
Donate Us With


