In Markdown there is two ways to place a link, one is to just type the raw link in, like: http://example.com, the other is to use the ()[] syntax: (Stack Overflow)[http://example.com ].
I'm trying to write a regular expression that can match both of these, and, if it's the second match to also capture the display string.
So far I have this:
(?P<href>http://(?:www\.)?\S+.com)|(?<=\((.*)\)\[)((?P=href))(?=\])
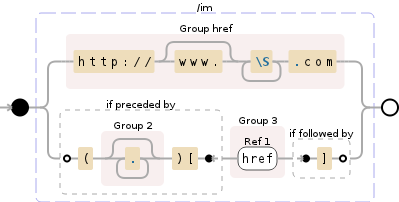
Debuggex Demo
But this doesn't seem to match either of my two test cases in Debuggex:
http://example.com
(Example)[http://example.com]
Really not sure why the first one isn't matched at the very least, is it something to do with my use of the named group? Which, if possible I'd like to keep using because this is a simplified expression to match the link and in the real example it is too long for me to feel comfortable duplicating it in two different places in the same pattern.
What am I doing wrong? Or is this not doable at all?
EDIT: I'm doing this in Python so will be using their regex engine.
Throw in an * (asterisk), and it will match everything. Read more. \s (whitespace metacharacter) will match any whitespace character (space; tab; line break; ...), and \S (opposite of \s ) will match anything that is not a whitespace character.
Most characters, including all letters ( a-z and A-Z ) and digits ( 0-9 ), match itself. For example, the regex x matches substring "x" ; z matches "z" ; and 9 matches "9" . Non-alphanumeric characters without special meaning in regex also matches itself. For example, = matches "=" ; @ matches "@" .
Markdown is a markup language used for formatting text in input fields where common tools for text formats are missing. For example, Markdown can be used to create headings or bold, italic or linked text. The syntax is simplified compared to html code.
Writing a regular expression that matches Markdown links in a string can seem to be straightforward. We can translate the pattern that we see as humans to a regex: square brackets with text inside followed by parentheses with text inside and possibly followed by a space and some text between double quotes. This gives the following regex:
Here, we want to find a certain pattern in markdownText and perform replace operations. Our markdown parser is simple. It captures a pattern from markdown string passed to the function as markdownText argument and replaces it with certain HTML pattern. Here is how the string replace function works.
Some of the popular websites that support rich text like Reddit, GitHub, Notion etc allow you to write markdown. I use markdown to convert my blog from a markdown file to HTML web pages. Markdown is simple yet very powerful.
This is how the regular expression schema looks on Debuggex: There are 4 capturing groups (surrounded by parenthesis) in that regex: Group 1 is the text of the link. Group 2 is the URL of the link. Group 3 is the optional title of the link including the double quotes (this group is necessary for the ? marker).
The reason your pattern doesn't work is here: (?<=\((.*)\)\[) since the re module of Python doesn't allow variable length lookbehind.
You can obtain what you want in a more handy way using the new regex module of Python (since the re module has few features in comparison).
Example: (?|(?<txt>(?<url>(?:ht|f)tps?://\S+(?<=\P{P})))|\(([^)]+)\)\[(\g<url>)\])
An online demo
pattern details:
(?| # open a branch reset group
# first case there is only the url
(?<txt> # in this case, the text and the url
(?<url> # are the same
(?:ht|f)tps?://\S+(?<=\P{P})
)
)
| # OR
# the (text)[url] format
\( ([^)]+) \) # this group will be named "txt" too
\[ (\g<url>) \] # this one "url"
)
This pattern uses the branch reset feature (?|...|...|...) that allows to preserve capturing groups names (or numbers) in an alternation. In the pattern, since the ?<txt> group is opened at first in the first member of the alternation, the first group in the second member will have the same name automatically. The same for the ?<url> group.
\g<url> is a reference to the named subpattern ?<url> (like an alias, in this way, no need to rewrite it in the second member.)
(?<=\P{P}) checks if the last character of the url is not a punctuation character (useful to avoid the closing square bracket for example). (I'm not sure of the syntax, it may be \P{Punct})
If you love us? You can donate to us via Paypal or buy me a coffee so we can maintain and grow! Thank you!
Donate Us With

