I want to create some sample programs that deal with encodings, specifically I want to use wide strings like:
wstring a=L"grüÃen";
wstring b=L"ש××× ×¢×××!";
wstring c=L"ä¸æ";
Because these are example programs.
This is absolutely trivial with gcc that treats source code as UTF-8 encoded text. But, straightforward compilation does not work under MSVC. I know that I can encode them using escape sequences but I would prefer to keep them as readable text.
Is there any option that I can specify as command line switch for "cl" in order to
make this work? There are there any command line switch like gcc'c -finput-charset?
If not how would you suggest make the text natural for user?
Note: adding BOM to UTF-8 file is not an option because it becomes non-compilable by other compilers.
Note2: I need it to work in MSVC Version >= 9 == VS 2008
The real answer: There is no solution
For those who subscribe to the motto "better late than never", Visual Studio 2015 (version 19 of the compiler) now supports this.
The new /source-charset command line switch allows you to specify the character set encoding used to interpret source files. It takes a single parameter, which can be either the IANA or ISO character set name:
/source-charset:utf-8
or the decimal identifier of a particular code page (preceded by a dot):
/source-charset:.65001
The official documentation is here, and there is also a detailed article describing these new options on the Visual C++ Team Blog.
There is also a complementary /execution-charset switch that works in exactly the same way but controls how narrow character- and string-literals are generated in the executable. Finally, there is a shortcut switch, /utf-8, that sets both /source-charset:utf-8 and /execution-charset:utf-8.
These command-line options are incompatible with the old #pragma setlocale and #pragma execution-character-set directives, and they apply globally to all source files.
For users stuck on older versions of the compiler, the best option is still to save your source files as UTF-8 with a BOM (as other answers have suggested, the IDE can do this when saving). The compiler will automatically detect this and behave appropriately. So, too, will GCC, which also accepts a BOM at the start of source files without choking to death, making this approach functionally portable.
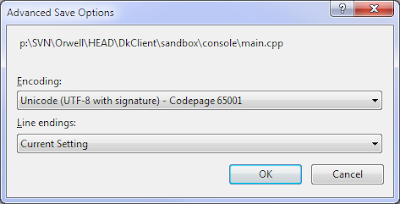
Open File->Advances Save Options...
Select Unicode(UTF-8 with signature) - Codepage 65001 in Encoding combo. Compiler will use selected encoding automatically.
According to Microsoft answer here:
if you want non-ASCII characters then the "official" and portable way to get them is to use the \u (or \U) hex encoding (which is, I agree, just plain ugly and error prone).
The compiler when faced with a source file that does not have a BOM the compiler reads ahead a certain distance into the file to see if it can detect any Unicode characters - it specifically looks for UTF-16 and UTF-16BE - if it doesn't find either then it assumes that it has MBCS. I suspect that in this case that in this case it falls back to MBCS and this is what is causing the problem.
Being explicit is really best and so while I know it is not a perfect solution I would suggest using the BOM.
Jonathan Caves
Visual C++ Compiler Team.
Good solution will be placing text strings in resource files. It is convenient and portable way. You could use localization libraries, such as gettext to manage translations.
The flow we used: save files as UTF8-with BOM, share the same source between linux and windows, for linux: preprocess the source files on compilation command in order to remove the BOM, run g++ on the intermediate non-BOM file.
For VS you can use:
#pragma setlocale( "[locale-string]" )
The default ANSI code page of the locale will be used as file encoding.
But in general is a bad idea to hard-code any user-visible strings in your code. Store them in some kind of resources. Good for localization, easy spell-checking and updating, etc.
IMHO all C++ source files should be in strict ASCII. Comments can be in UTF-8 if the editor supports it.
This makes the code portable across platforms, editors and source control systems.
You can use \u to insert Unicode characters into a wide string:
std::wstring str = L"\u20AC123,00"; //â¬123,00
If you love us? You can donate to us via Paypal or buy me a coffee so we can maintain and grow! Thank you!
Donate Us With





