I have the following problem.
I have a set of elements that I can sort by a certain algorithm A . The sorting is good, but very expensive.
There is also an algorithm B that can approximate the result of A. It is much faster, but the ordering will not be exactly the same.
Taking the output of A as a 'golden standard' I need to get a meaningful estimate of the error resulting of the use of B on the same data.
Could anyone please suggest any resource I could look at to solve my problem? Thanks in advance!
EDIT :
As requested : adding an example to illustrate the case : if the data are the first 10 letters of the alphabet,
A outputs : a,b,c,d,e,f,g,h,i,j
B outputs : a,b,d,c,e,g,h,f,j,i
What are the possible measures of the resulting error, that would allow me to tune the internal parameters of algorithm B to get result closer to the output of A?
I think what you want is Spearman's rank correlation coefficient. Using the index [rank] vectors for the two sortings (perfect A and approximate B), you calculate the rank correlation rho ranging from -1 (completely different) to 1 (exactly the same):
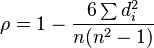
where d(i) are the difference in ranks for each character between A and B
You can defined your measure of error as a distance D := (1-rho)/2.
If you love us? You can donate to us via Paypal or buy me a coffee so we can maintain and grow! Thank you!
Donate Us With

