The last couple of days we are thinking of using Solr as our search engine of choice. Most of the features we need are out of the box or can be easily configured. There is however one feature that we absolutely need that seems to be well hidden (or missing) in Solr.
I'll try to explain with an example. We have lots of documents that are actually businesses:
<document>
<name>Apache</name>
<cat>1</cat>
...
</document>
<document>
<name>McDonalds</name>
<cat>2</cat>
...
</document>
In addition we have another xml file with all the categories and synonyms:
<cat id=1>
<name>software</name>
<synonym>IT<synonym>
</cat>
<cat id=2>
<name>fast food</name>
<synonym>restaurant<synonym>
</cat>
We want to associate both businesses and categories so we can search using the name and/or synonyms of the category. But we do not want to merge these files at indexing time because we should update the categories (adding.remioving synonyms...) without indexing all the businesses again.
Is there anything in Solr that does this kind of associations or do we need to develop some specific pieces?
All feedback and suggestions are welcome.
Thanks in advance, Tom
Clients use Solr's five fundamental operations to work with Solr. The operations are query, index, delete, commit, and optimize. Queries are executed by creating a URL that contains all the query parameters. Solr examines the request URL, performs the query, and returns the results.
MTV uses Solr to power search on a number of its websites. NASA is using Solr as the Enterprise Search component in its NEBULA cloud computing platform. Netflix uses Solr for their site search feature.
We have compiled a list of solutions that reviewers voted as the best overall alternatives and competitors to Apache Solr, including Algolia, Elastic Observability, Coveo, and Yext.
So, it's not accurate to say that "Google chose Solr," but it is accurate to suggest that All for Good was founded by Googlers in their "20-percent time" and continues to be hosted by Google, as TechCrunch has reported, and that those Googlers, along with the rest of the board, opted for Solr over Google.
Basically you have a design decision here. The usual thing people do with Solr indexes is to denormalize them, i.e. explode the category definition into the business' document. As you do not want to do this, I suggest keeping two types of documents - one for the businesses and another for the categories.You can keep both in the same index, as Solr does not require all documents to have the same fields. The business documents seem straightforward, but you have to make them searchable by both the business name and the category id. I suggest creating a category document for each synonym, where you search by synonym and find the id (and category name).
To search using synonyms, you will need a double search -
There is actually a filter class called solr.SynonymFilterFactory.
This should allow you to map the cat numbers to its 2 text equivalents, if you use it in the query analyser only, something like the following:
<fieldType name="category" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="1" catenateNumbers="1" catenateAll="0" splitOnCaseChange="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.SynonymFilterFactory" synonyms="category_Synonyms.txt" ignoreCase="true" expand="false"/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="0" catenateNumbers="0" catenateAll="0" splitOnCaseChange="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
That way you can index ONLY the category ID. This means you won't have to send all the businesses to Solr again. Also if someone queries "software"or "IT" it will map it to the category
Your category_Synonyms.txt should have lines such as the following:
1, software, IT
The onlydraw back here is that you'll have to come up with a way of editing the text document when you change the names or synonyms. So i guess this will only help if you change the category names infrequently?? Unless someone else knows of a way that this can be done easily.
I actually added the above to my own solr and ran the Analyser tool on it.. here is the result:
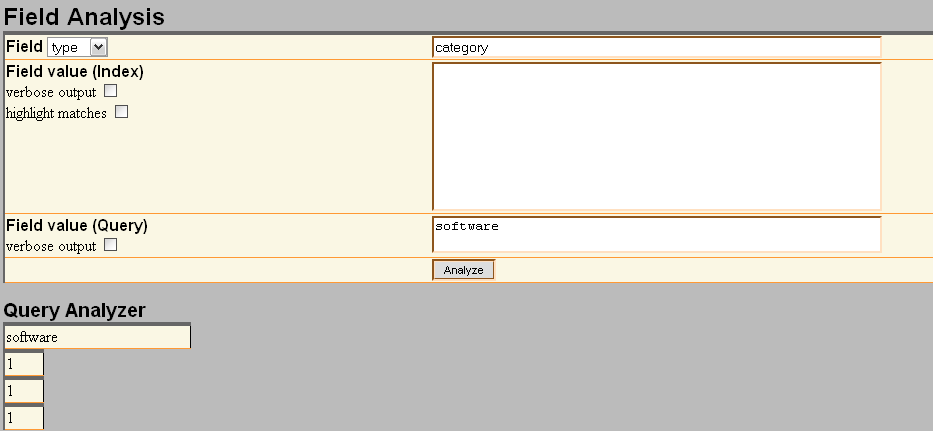
As you can see it's turned software into
1
Please note you MUST set the
expand
parameter to
false
I hope this helps.
Dave
If you love us? You can donate to us via Paypal or buy me a coffee so we can maintain and grow! Thank you!
Donate Us With


