A question that I answered got me wondering:
How are regular expressions implemented in Python? What sort of efficiency guarantees are there? Is the implementation "standard", or is it subject to change?
I thought that regular expressions would be implemented as DFAs, and therefore were very efficient (requiring at most one scan of the input string). Laurence Gonsalves raised an interesting point that not all Python regular expressions are regular. (His example is r"(a+)b\1", which matches some number of a's, a b, and then the same number of a's as before). This clearly cannot be implemented with a DFA.
So, to reiterate: what are the implementation details and guarantees of Python regular expressions?
It would also be nice if someone could give some sort of explanation (in light of the implementation) as to why the regular expressions "cat|catdog" and "catdog|cat" lead to different search results in the string "catdog", as mentioned in the question that I referenced before.
A regular expression is a method used in programming for pattern matching. Regular expressions provide a flexible and concise means to match strings of text. For example, a regular expression could be used to search through large volumes of text and change all occurrences of "cat" to "dog".
Regular expressions are useful in any scenario that benefits from full or partial pattern matches on strings. These are some common use cases: verify the structure of strings. extract substrings form structured strings.
The () will allow you to read exactly which characters were matched. Parenthesis are also useful for OR'ing two expressions with the bar | character. For example, (a-z|0-9) will match one character -- any of the lowercase alpha or digit.
Python's re module was based on PCRE, but has moved on to their own implementation.
Here is the link to the C code.
It appears as though the library is based on recursive backtracking when an incorrect path has been taken.
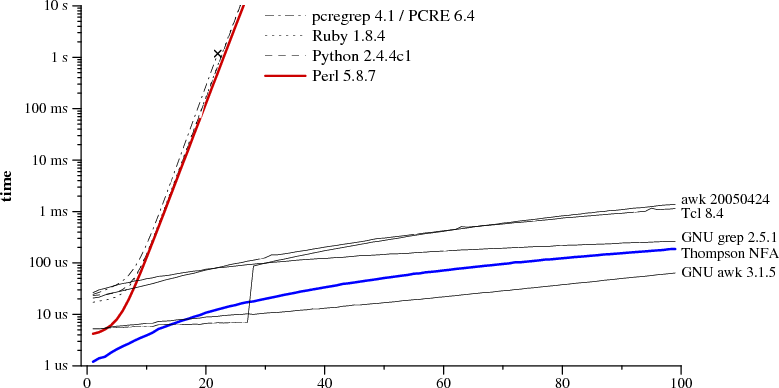
Regular expression and text size n
a?nan matching an
Keep in mind that this graph is not representative of normal regex searches.
http://swtch.com/~rsc/regexp/regexp1.html
There are no "efficiency guarantees" on Python REs any more than on any other part of the language (C++'s standard library is the only widespread language standard I know that tries to establish such standards -- but there are no standards, even in C++, specifying that, say, multiplying two ints must take constant time, or anything like that); nor is there any guarantee that big optimizations won't be applied at any time.
Today, F. Lundh (originally responsible for implementing Python's current RE module, etc), presenting Unladen Swallow at Pycon Italia, mentioned that one of the avenues they'll be exploring is to compile regular expressions directly to LLVM intermediate code (rather than their own bytecode flavor to be interpreted by an ad-hoc runtime) -- since ordinary Python code is also getting compiled to LLVM (in a soon-forthcoming release of Unladen Swallow), a RE and its surrounding Python code could then be optimized together, even in quite aggressive ways sometimes. I doubt anything like that will be anywhere close to "production-ready" very soon, though;-).
If you love us? You can donate to us via Paypal or buy me a coffee so we can maintain and grow! Thank you!
Donate Us With


