So I think I'm going to get buried for asking such a trivial question but I'm a little confused about something.
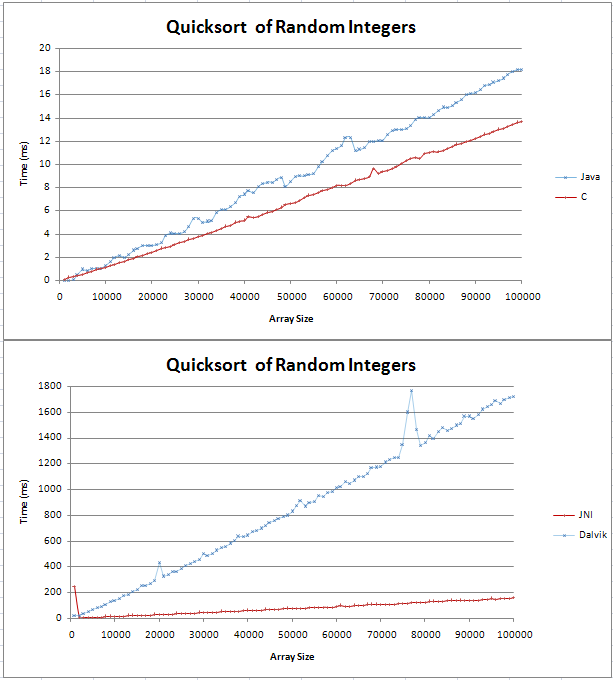
I have implemented quicksort in Java and C and I was doing some basic comparissons. The graph came out as two straight lines, with the C being 4ms faster than the Java counterpart over 100,000 random integers.
The code for my tests can be found here;
android-benchmarks
I wasn't sure what an (n log n) line would look like but I didn't think it would be straight. I just wanted to check that this is the expected result and that I shouldn't try to find an error in my code.
I stuck the formula into excel and for base 10 it seems to be a straight line with a kink at the start. Is this because the difference between log(n) and log(n+1) increases linearly?
Thanks,
Gav
So what is O(n log n)? Well, it's just that. It's n, a linear time complexity, multiplied by log n, a logarithmic time complexity.
Yes constant time i.e. O(1) is better than linear time O(n) because the former is not depending on the input-size of the problem. The order is O(1) > O (logn) > O (n) > O (nlogn).
Logarithmic time complexity log(n): Represented in Big O notation as O(log n), when an algorithm has O(log n) running time, it means that as the input size grows, the number of operations grows very slowly. Example: binary search.
O(logn) means that the algorithm's maximum running time is proportional to the logarithm of the input size. O(n) means that the algorithm's maximum running time is proportional to the input size.
Make the graph bigger and you'll see that O(n logn) isn't quite a straight line. But yes, it is pretty near to linear behaviour. To see why, just take the logarithm of a few very large numbers.
For example (base 10):
log(1000000) = 6 log(1000000000) = 9 … So, to sort 1,000,000 numbers, an O(n logn) sorting adds a measly factor 6 (or just a bit more since most sorting algorithms will depend on base 2 logarithms). Not an awful lot.
In fact, this log factor is so extraordinarily small that for most orders of magnitude, established O(n logn) algorithms outperform linear time algorithms. A prominent example is the creation of a suffix array data structure.
A simple case has recently bitten me when I tried to improve a quicksort sorting of short strings by employing radix sort. Turns out, for short strings, this (linear time) radix sort was faster than quicksort, but there was a tipping point for still relatively short strings, since radix sort crucially depends on the length of the strings you sort.
If you love us? You can donate to us via Paypal or buy me a coffee so we can maintain and grow! Thank you!
Donate Us With

