this regular expression should match an html start tag, I think.
var results = html.match(/<(\/?)(\w+)([^>]*?)>/);
I see it should first capture the <, but then I am confused what this capture (\/?) accomplishes. Am I correct in reasoning that the ([^>]*?)> searches for every character except > >= 0 times? If so, why is the (\w+) capture necessary? Doesn't it fall within the purview of [^>]*?
In regex, the uppercase metacharacter denotes the inverse of the lowercase counterpart, for example, \w for word character and \W for non-word character; \d for digit and \D or non-digit.
\w -- (lowercase w) matches a "word" character: a letter or digit or underbar [a-zA-Z0-9_]. Note that although "word" is the mnemonic for this, it only matches a single word char, not a whole word. \W (upper case W) matches any non-word character.
The Match-zero-or-more Operator ( * ) This operator repeats the smallest possible preceding regular expression as many times as necessary (including zero) to match the pattern. `*' represents this operator. For example, `o*' matches any string made up of zero or more `o' s.
Definition and Usage The \w metacharacter matches word characters. A word character is a character a-z, A-Z, 0-9, including _ (underscore).
Take it token by token:
/ begin regex literal< match a literal <
(\/?) match 0 or 1 (?) literal /, which is escaped by the \
(\w+) match one or more "word characters"([^>]*?) lazily* match zero or more (*?) of anything that is not a >
> match a literal >
/ end regex literallazily* - adding "?" after a repetition quantifier will make it perform lazily, meaning the regex will match the preceding token the minimum number of times. See the documentation.
So essentially this regular expression will match "<", potentially followed by a "/", followed by any number of letters, digits, or underscores, followed by anything that is not a ">", and finally followed by a ">".
That being said, the token (\w+) is not redundant, as it ensures there is at least one word character in between < and >.
Please be aware that attempting to parse HTML with regular expressions is generally a bad idea.
Using the power of debuggex to generate you an image :)
<(\/?)(\w+)([^>]*?)>
Will be evaluated like this
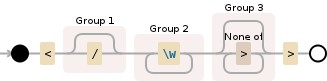
Edit live on Debuggex
As you can see, it matches HTML-tags (opening and closing tags). The regex contains three capture groups, capturing the following:
(\/?) existence of / (it's a closing tag, if present)(\w+) name of the tag([^>]*?) everything else until the tag closes (e.g. attributes)This way it matches <a href="#">. Interestingly it does not match <a data-fun="fun>nofun"> correctly because it stops at the > within the data-fun attribute. Although (I think) > is valid in an attribute value.
Another funny thing is, that the tag-name capture, does not capture all theoretically valid XHTML tags. XHTML allows Letter | Digit | '.' | '-' | '_' | ':' | .. (source: XHTML spec). (\w+), however, does not match ., -, and :. An imaginary <.foobar> tag will not be matched by this regex. This should not have any real life impact, though.
You see that parsing HTML using RgExes is a risky thing. You might be better of with a HTML parser.
If you love us? You can donate to us via Paypal or buy me a coffee so we can maintain and grow! Thank you!
Donate Us With


