I am trying to teach my camera to be a scanner: I take pictures of printed text and then convert them to bitmaps (and then to djvu and OCR'ed). I need to compute a threshold for which pixels should be white and which black, but I'm stymied by uneven illumination. For example if the pixels in the center are dark enough, I'm likely to wind up with a bunch of black pixels in the corners.
What I would like to do, under relatively simple assumptions, is compensate for uneven illumination before thresholding. More precisely:
Assume one or two light sources, maybe one with gradual change in light intensity across the surface (ambient light) and another with an inverse square (direct light).
Assume that the white parts of the paper all have the same reflectivity/albedo/whatever.
Find some algorithm to estimate degree of illumination at each pixel, and from that recover the reflectivity of each pixel.
From a pixel's reflectivity, classify it white or black
I have no idea how to write an algorithm to do this. I don't want to fall back on least-squares fitting since I'd somehow like to ignore the dark pixels when estimating illumination. I also don't know if the algorithm will work.
All helpful advice will be upvoted!
EDIT: I've definitely considered chopping the image into pieces that are large enough so they still look like "text on a white background" but small enough so that illumination of a single piece is more or less even. I think if I then interpolate the thresholds so that there's no discontinuity across sub-image boundaries, I will probably get something halfway decent. This is a good suggestion, and I will have to give it a try, but it still leaves me with the problem of where to draw the line between white and black. More thoughts?
EDIT: Here are some screen dumps from GIMP showing different histograms and the "best" threshold value (chosen by hand) for each histogram. In two of the three a single threshold for the whole image is good enough. In the third, however, the upper left corner really needs a different threshold:
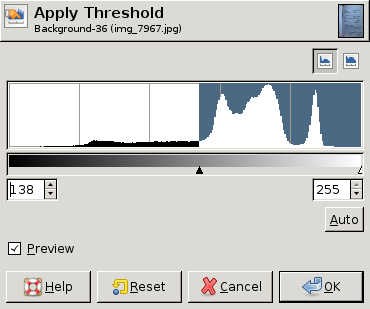
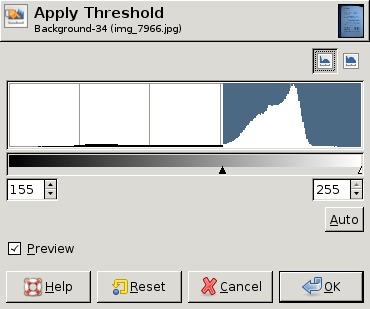
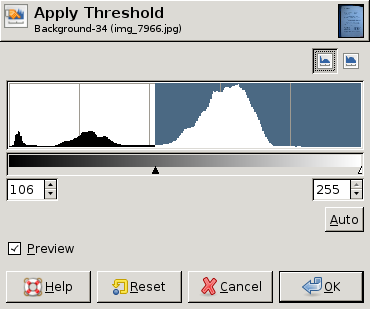
I'm not sure if you still need a solution after all this time, but if you still do. A few years ago I and my team photographed about 250,000 pages with a camera and converted them to (almost black and white ) grey scale images which we then DjVued ( also make pdfs of).
(See The catalogue and complete collection of photographic facsimiles of the 1144 paper transcripts of the French Institute of Pondicherry.)
We also ran into the problem of uneven illumination. We came up with a simple unsophisticated solution which worked very well in practice. This solution should also work to create black and white images rather than grey scale (as I'll describe).
The camera and lighting setup
a) We taped an empty picture frame to the top of a table to keep our pages in the exact same position.
b) We put a camera on a tripod also on top of the table above and pointing down at the taped picture frame and on a bar about a foot wide attached to the external flash holder on top of the camera we attached two "modelling lights". These can be purchased at any good camera shop. They are designed to provide even illumination. The camera was shaded from the lights by putting small cardboard box around each modelling light. We photographed in greyscale which we then further processed. (Our pages were old browned paper with blue ink writing so your case should be simpler).
Processing of the images
We used the free software package irfanview.
This software has a batch mode which can simultaneously do color correction, change the bit depth and crop the images. We would take the photograph of a page and then in interactive mode adjust the brightness, contrast and gamma settings till it was close to black and white. (We used greyscale but by setting the bit depth to 2 you will get black and white when you batch process all the pages.) After determining the best color correction we then interactively cropped a single image and noted the cropping settings. We then set all these settings in the batch mode window and processed the pages for one book.
Creating DjVu images.
We used the free DjVu Solo 3.1 to create the DjVu images. This has several modes to create the DjVu images. The mode which creates black and white images didn't work well for us for photographs, but the "photo" mode did.
We didn't OCR (since the images were handwritten Sanskrit) but as long as the letters are evenly illuminated I think your OCR software should ignore big black areas like between a two page spread. But you can always get rid of the black between a two page spread or at the edges by cropping the pages twices once for the left hand pages and once for the right hand pages and the irfanview software will allow you to cleverly number your pages so you can then remerge the pages in the correct order. I.e rename your pages something like page-xxxA for lefthand pages and page-xxxB for righthand pages and the pages will then sort correctly on name.
If you still need a solution I hope some of the above is useful to you.
i would recommend calibrating the camera. considering that your lighting setup is fixed (that is the lights do not move between pictures), and your camera is grayscale (not color).
take a picture of a white sheet of paper which covers the whole workable area of your "scanner". store this picture, it tells what is white paper for each pixel. now, when you take take a picture of a document to scan, you can reload your "white reference picture" and even the illumination before performing a threshold.
let's call the white reference REF, the picture DOC, the even illumination picture EVEN, and the maximum value of a pixel MAX (for 8bit imaging, it is 255). for each pixel:
EVEN = DOC * (MAX/REF)
notes:
If you love us? You can donate to us via Paypal or buy me a coffee so we can maintain and grow! Thank you!
Donate Us With


