A many-to-one relationship is where one entity (typically a column or set of columns) contains values that refer to another entity (a column or set of columns) that has unique values.
Here are some examples of one-to-one relationships in the home: One family lives in one house, and the house contains one family. One person has one passport, and the passport can only be used by one person. One person has one ID number, and the ID number is unique to one person.
Yes, it a vice versa. It depends on which side of the relationship the entity is present on.
For example, if one department can employ for several employees then, department to employee is a one to many relationship (1 department employs many employees), while employee to department relationship is many to one (many employees work in one department).
More info on the relationship types:
Database Relationships - IBM DB2 documentation
From this page about Database Terminology
Most relations between tables are one-to-many.
Example:
- One area can be the habitat of many readers.
- One reader can have many subscriptions.
- One newspaper can have many subscriptions.
A Many to One relation is the same as one-to-many, but from a different viewpoint.
- Many readers live in one area.
- Many subscriptions can be of one and the same reader.
- Many subscriptions are for one and the same newspaper.
What is the real difference between one-to-many and many-to-one relationship?
There are conceptual differences between these terms that should help you visualize the data and also possible differences in the generated schema that should be fully understood. Mostly the difference is one of perspective though.
In a one-to-many relationship, the local table has one row that may be associated with many rows in another table. In the example from SQL for beginners, one Customer may be associated to many Orders.
In the opposite many-to-one relationship, the local table may have many rows that are associated with one row in another table. In our example, many Orders may be associated to one Customer. This conceptual difference is important for mental representation.
In addition, the schema which supports the relationship may be represented differently in the Customer and Order tables. For example, if the customer has columns id and name:
id,name
1,Bill Smith
2,Jim Kenshaw
Then for a Order to be associated with a Customer, many SQL implementations add to the Order table a column which stores the id of the associated Customer (in this schema customer_id:
id,date,amount,customer_id
10,20160620,12.34,1
11,20160620,7.58,1
12,20160621,158.01,2
In the above data rows, if we look at the customer_id id column, we see that Bill Smith (customer-id #1) has 2 orders associated with him: one for $12.34 and one for $7.58. Jim Kenshaw (customer-id #2) has only 1 order for $158.01.
What is important to realize is that typically the one-to-many relationship doesn't actually add any columns to the table that is the "one". The Customer has no extra columns which describe the relationship with Order. In fact the Customer might also have a one-to-many relationship with ShippingAddress and SalesCall tables and yet have no additional columns added to the Customer table.
However, for a many-to-one relationship to be described, often an id column is added to the "many" table which is a foreign-key to the "one" table -- in this case a customer_id column is added to the Order. To associated order #10 for $12.34 to Bill Smith, we assign the customer_id column to Bill Smith's id 1.
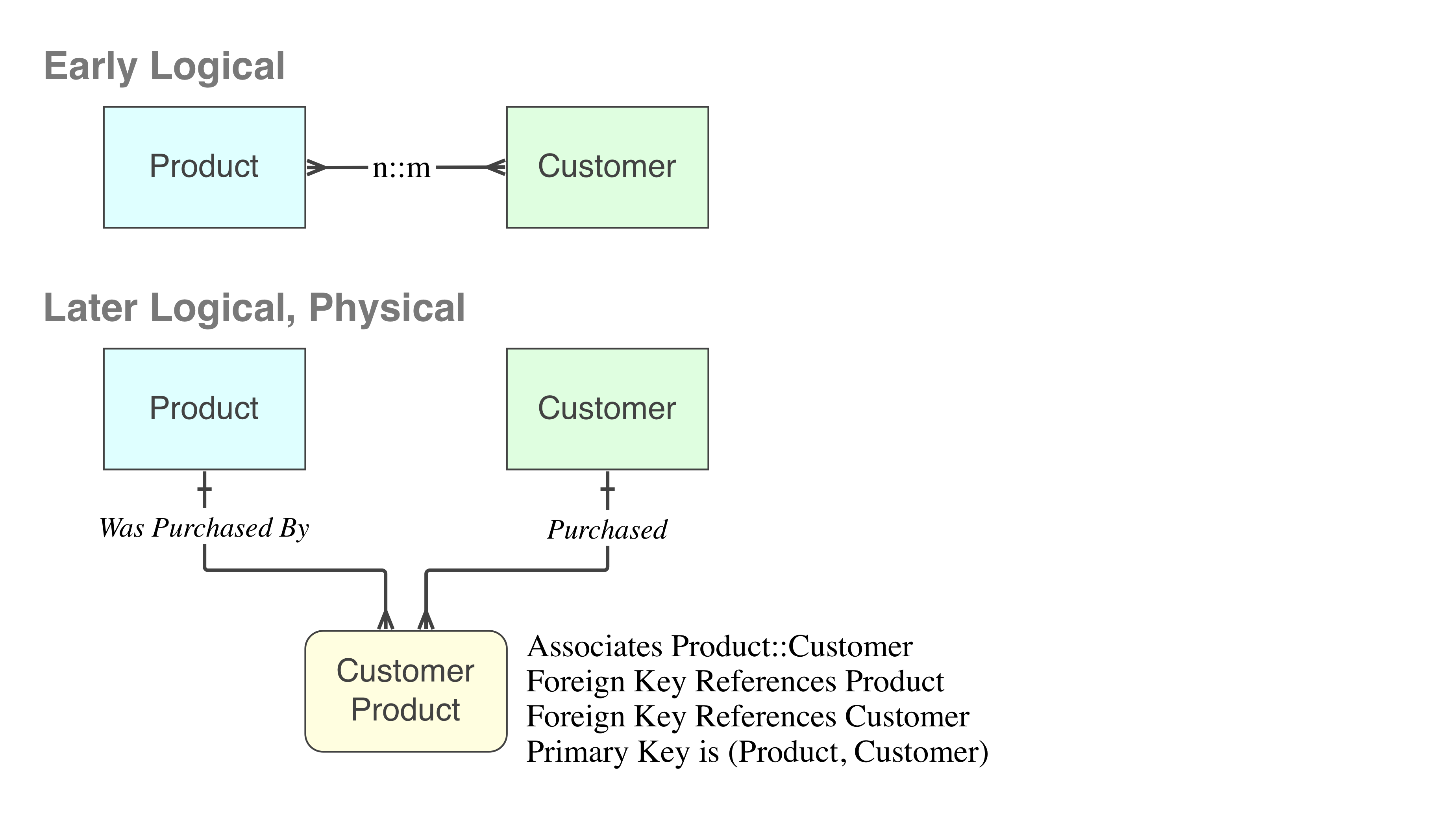
However, it is also possible for there to be another table that describes the Customer and Order relationship, so that no additional fields need to be added to the Order table. Instead of adding a customer_id field to the Order table, there could be Customer_Order table that contains keys for both the Customer and Order.
customer_id,order_id
1,10
1,11
2,12
In this case, the one-to-many and many-to-one is all conceptual since there are no schema changes between them. Which mechanism depends on your schema and SQL implementation.
Hope this helps.

In SQL, there is only one kind of relationship, it is called a Reference. (Your front end may do helpful or confusing things [such as in some of the Answers], but that is a different story.)
A Foreign Key in one table (the referencing table)
References
a Primary Key in another table (the referenced table)
In SQL terms, Bar references Foo
Not the other way around
CREATE TABLE Foo (
Foo CHAR(10) NOT NULL, -- primary key
Name CHAR(30) NOT NULL
CONSTRAINT PK -- constraint name
PRIMARY KEY (Foo) -- pk
)
CREATE TABLE Bar (
Bar CHAR(10) NOT NULL, -- primary key
Foo CHAR(10) NOT NULL, -- foreign key to Foo
Name CHAR(30) NOT NULL
CONSTRAINT PK -- constraint name
PRIMARY KEY (Bar), -- pk
CONSTRAINT Foo_HasMany_Bars -- constraint name
FOREIGN KEY (Foo) -- fk in (this) referencing table
REFERENCES Foo(Foo) -- pk in referenced table
)
Since Foo.Foo is a Primary Key, it is unique, there is only one row for any given value of Foo
Since Bar.Foo is a Reference, a Foreign Key, and there is no unique index on it, there can be many rows for any given value of Foo
Therefore the relation Foo::Bar is one-to-many
Now you can perceive (look at) the relation the other way around, Bar::Foo is many-to-one
Bar row, there is just one Foo row that it ReferencesIn SQL, that is all we have. That is all that is necessary.
What is the real difference between one to many and many to one relationship?
There is only one relation, therefore there is no difference. Perception (from one "end" or the other "end") or reading it backwards, does not change the relation.
Cardinality is declared first in the data model, which means Logical and Physical (the intent), and then in the implementation (the intent realised).
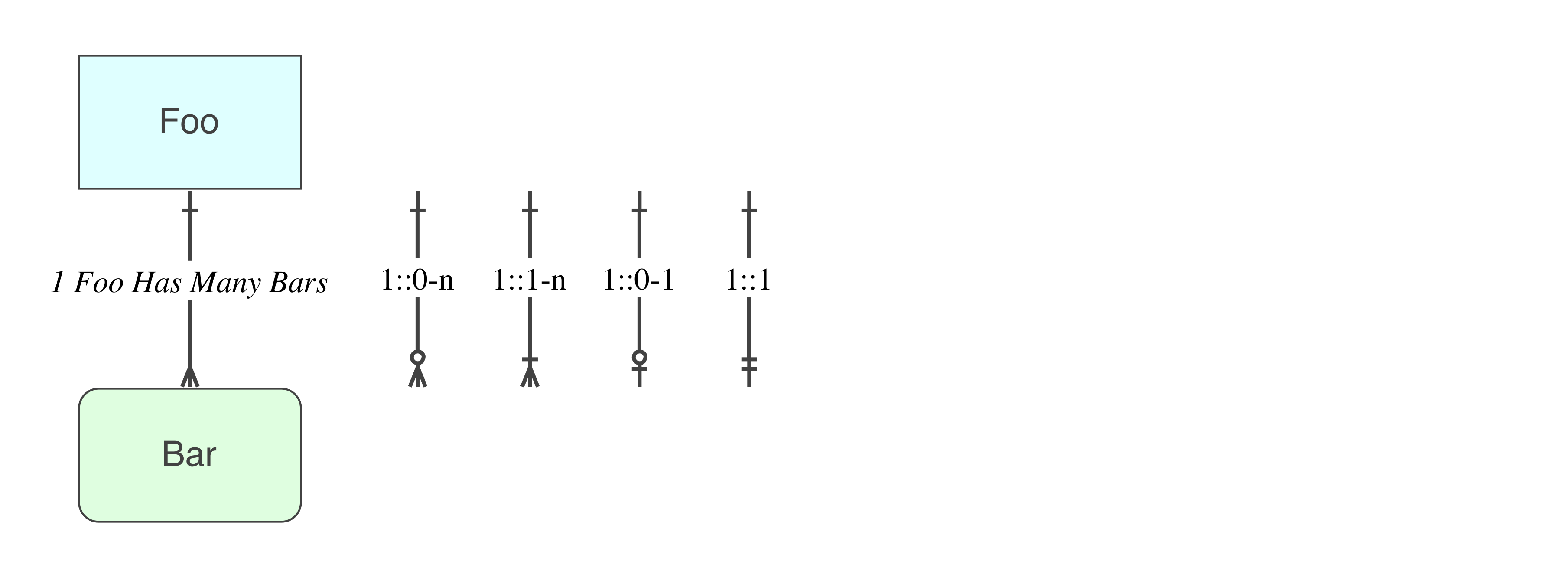
One to zero-to-many
In SQL that (the above) is all that is required.
One to one-to-many
You need a Transaction to enforce the one in the Referencing table.
One to zero-to-one
You need in Bar:
CONSTRAINT AK -- constraint name
UNIQUE (Foo) -- unique column, which makes it an Alternate Key
One to one
You need a Transaction to enforce the one in the Referencing table.
There is no such thing at the Physical level (recall, there is only one type of relation in SQL).
At the early Logical levels during the modelling exercise, it is convenient to draw such a relation. Before the model gets close to implementation, it had better be elevated to using only things that can exist. Such a relation is resolved by implementing an Associative Table at the physical [DDL] level.
If you love us? You can donate to us via Paypal or buy me a coffee so we can maintain and grow! Thank you!
Donate Us With