I know that normalization has been extensively discussed on Stack Overflow. I've read many of the previous discussions. I've got some additional questions though.
I'm working on a legacy system with at least 100 tables. The database is has some un-normalized structure, tables that contain a variety of disparate data, and other problems. I've been given the task of trying to improve it. I can't just start again but need to modify the existing schema.
In the past I have always tried to design normalized databases. Now the questions. A senior developer has suggested that in some cases we can't normalize:
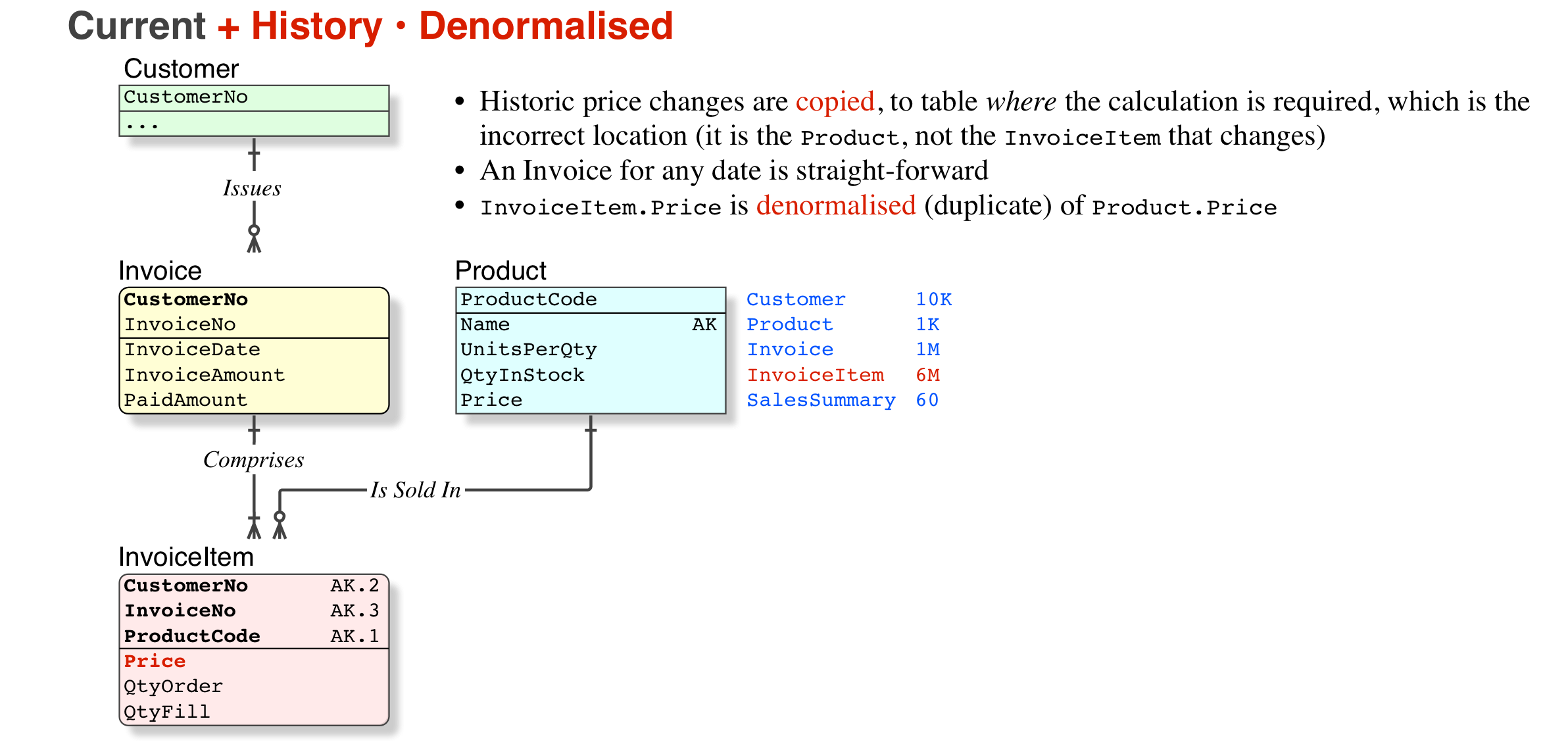
With temporal data. For example an invoice is created that links to a product. If a customer asks for a copy of this invoice a year later we must be able to produce an exact copy of the original. What if the product price, name or description have been updated? The senior guy suggested that the price and other product information should be copied to the invoice table. I'm thinking maybe we should have another table such as productPrice that has a date field so we can track changes in price over time. We would need the same thing for the product description and name I guess? Seems complicated. What do you think?
The database is an accounting system. I'm not very familiar with accounting. At the moment some summary data is derived and stored in the database. For example total sales for the year. My senior associate has said that accountants like to check things are correct by comparing this value with data that is actually calculated from invoices etc to give them confidence that the application is working correctly.
He said that at the moment for example we can tell if someone deleted an invoice from last year mistakenly because the totals will not be the same. He also pointed out that it could be quite slow to calculate these totals on the fly. Of course I said that data should not be duplicated and should always be calculated when needed. I suggested that we could use SQL Reporting Services or some other solution that will generate these reports overnight and cache them. Anyway he's not convinced. Any comments on this?
Data Denormalization is a technique used on a previously-normalized database to increase the performance. In computing, denormalization is the process of improving the read performance of a database, at the expense of losing some write performance, by adding redundant copies of data or by grouping it.
Denormalization is a database optimization technique in which we add redundant data to one or more tables. This can help us avoid costly joins in a relational database.
Normalization is used when the faster insertion, deletion and update anomalies, and data consistency are necessarily required. On the other hand, Denormalization is used when the faster search is more important and to optimize the read performance.
Disadvantages of Denormalization As data redundancy is there, update and insert operations are more expensive and take more time. Since we are not performing normalization, so this will result in redundant data. Data Integrity is not maintained in denormalization. As there is redundancy so data can be inconsistent.
Your senior colleague is a developer, not a data modeller. You are better off starting from scratch, without them. Normalisation is complicated only to those who will not read books. It is fair enough that he makes you think, but some of the issues are absurd.
Your numbers:
You need to appreciate the differences between actual online data, and historic data; then the difference between merely historic and archival needs. All of them are right for the specific business requirement, and wrong for all others, there is no universal right and wrong.
ProductPrice (actually, I would call it ProductDate) is a good idea, but may not be necessary. But you are right, you need to evaluate the currency of data, in the full context of the whole database.IsIssued/IsPaid/Etc Products cannot be deleted, they can be marked IsObsolete InvoiceItem has FKs to both InvoiceHeader and Product NumUnits; ProductPrice; TaxAmount; ExtendedPrice. Sure, this looks like a "denormalisation" but it is not, because prices, taxation rates, etc, are subject to change. But more important, the legal requirement is that we can reproduce the old invoice on demand.InvoiceTotalAmount is a derived column, just SUM() of the InvoiceItemsThat is rubbish. Accounting systems, and accountants do not "work" like that.
If it is a true accounting system, then it will have JournalEntries, or "double entry"; that is what a qualified account is required to use (by law).
Double Entry Accounting does not mean duplicate entries; it means every financial transaction (one amount) shall have a source account and target account that it is applied to; so there is no "denormalisation" or duplication. In a banking database, because the financial transactions are against single accounts, that is commonly rendered as two separate financial transactions (rows) within one Db Transaction. Ordinary commercial database constraints are used to ensure that there are two "sides" to every financial transaction.
Ensuring that Invoices are not deleteable is a separate issue, to do with security, etc. if anyone is paranoid about things being deleted from their database, and their database was not secured by a qualified person, then they have more and different problems that have nothing to do with this question. Obtain a security audit, and do whatever they tell you.
Wikipedia is not a reliable source of information about any technical subject, let alone Normalisation.
A Normalised database is always much faster than Un-Normalised database
So it is very important to understand what Normalisation and Denormalisaion is, and what it isn't. The process is greatly hindered when people have fluid and amateur "definitions", it just leads to confusion and time-wasting "discussions". When you have fixed definitions, you can avoid all that, and just get on with the job.
Summary tables are quite normal, to save the time and processing power, of recalculating info that does not change, eg: YTD totals for every year but this year; MTD totals for every month in this year but not this month. "Always recalculating" data is a bit silly when (a) the info is very large and (b) does not change. Calculate for the current month only
Summary tables are not a "denormalisation" (except in the eyes of those who have just learned about "normalisation" from their magical, ever-changing fluid "source"; or as non-practitioners, who apply simple black-or-white rules to everything). Again, the definition is not being argued here; it simply does not apply to Summary tables.
Summary tables do not affect data integrity (assuming of course that the data that they were sourced from was integral).
Summary tables are an addition to the current data, which are not required to have the same constraints as the current data. There are essentially reporting tables or data warehouse tables, as opposed to current data tables.
There are no Update Anomalies (which is a strict definition) related to Summary tables. You cannot change or delete an invoice from last year. Update Anomalies apply to true Denormalised or Un-Normalised current data.
so its ok to do denormalisation for the sakes of archiving right?
My explanation above appears not to be clear enough. Let's look at an example, and compare the options.

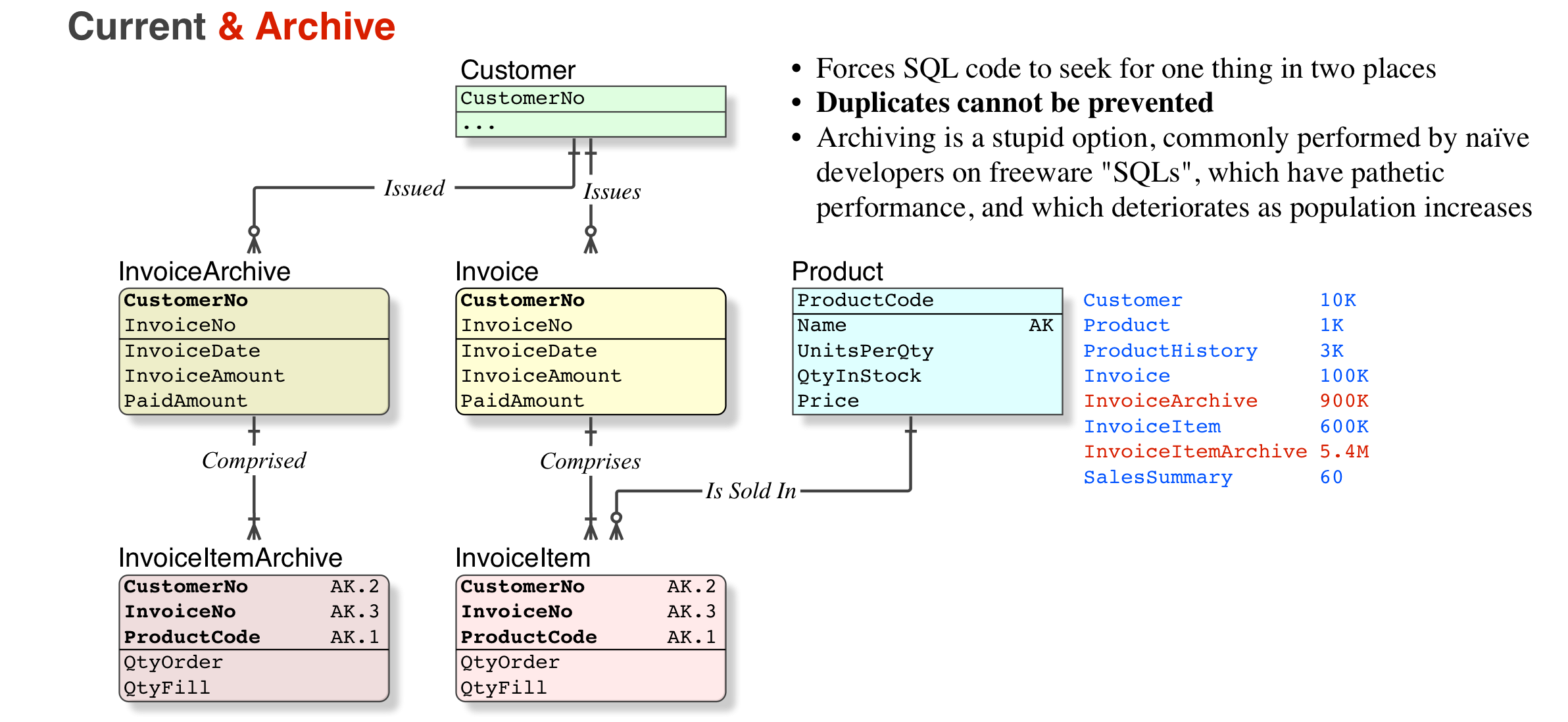
So, no. Archiving is a hideous option (I have corrected thousands of archived tables back to their home; corrected the indices, and restored normal performance, as well as returning the SELECT to query just one table instead of two). But if you do archive, it is not denormalised, it is worse, a copy.
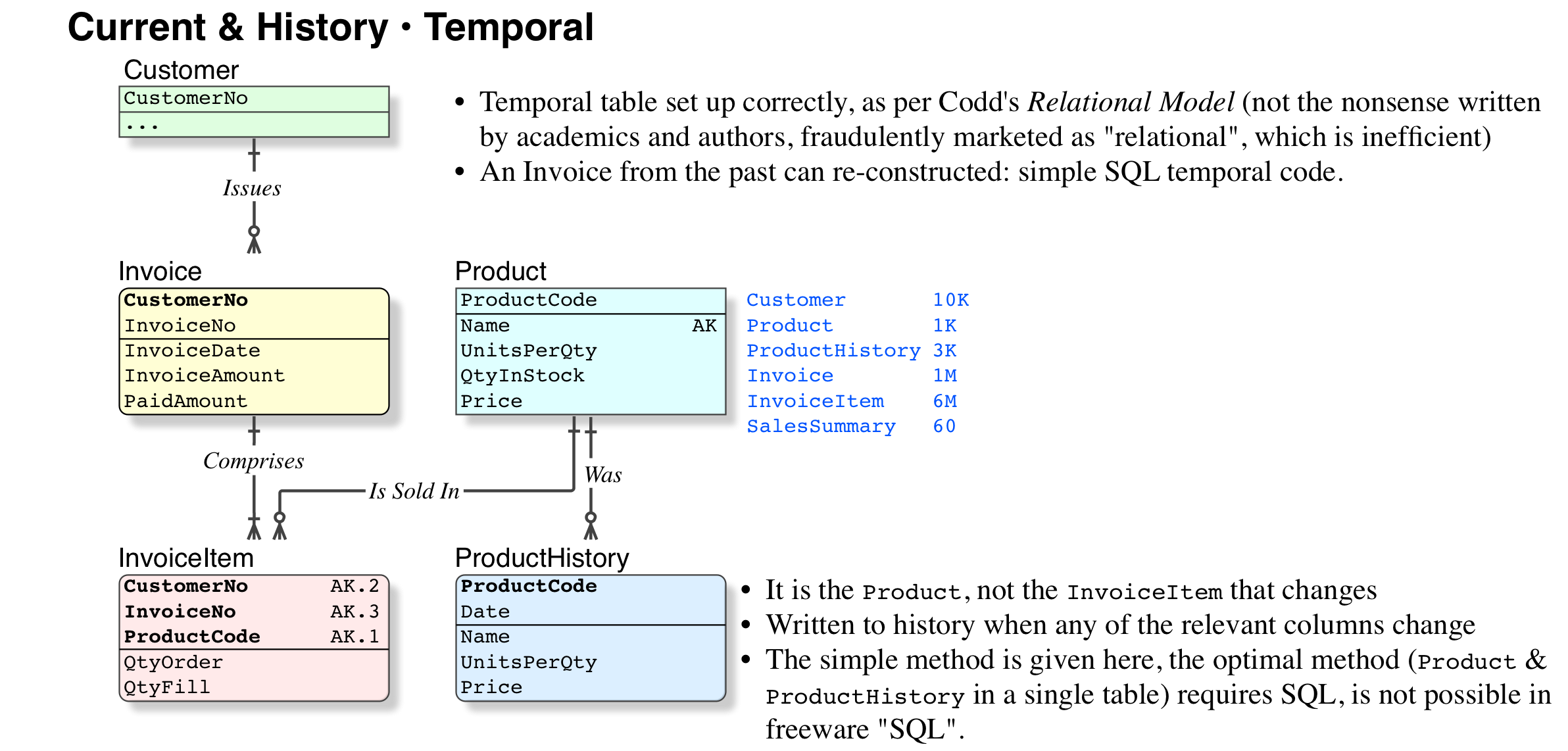
The best option by far. Again, this is the simple version, the full version requires an understanding of the temporal definition in Codd's Relational Model (not the ever-changing nonsense marketed by the detractors), and an SQL-compliant platform.
I disagree strongly with the statement that "A Normalised database is always much faster than Unnormalised database". That is patently false even if I don't harp on the use of "always". There are many scenarios in which selective, coherent denormalization of a database can result in extreme performance improvement.
Example [of justified De-Normalisation]: a complex join for a date-limited data set, like a month-end summary for a complex business. If the data is collected over the course of a month; then forever stable; and queried often — it can make sense to pre-compute via a materialized view, trigger, or more sophisticated method.
Evidently we need clear definitions.
Normalisation
Un-Normalised
Failure to Normalise properly, leaving Update Anomalies in the database, and makes a mess of the Transactions
De-Normalised
After formal Normalisation, one or more columns additionally placed in chosen tables, for performance reasons.
Summary Table/Materialised View
As detailed above in the Answer (please read again), and as illustrated in the graphic Current Only, it is an additional table to serve the purpose of providing summary values for history, that does not change. This is common.
You were not in disagreement with my statement [A Normalised database is always much faster than Unnormalised database], which relates to Normalised vs Un-Normalised, you were categorising the summary table incorrectly, as "de-Normalised".
If you can know in advance what complex, time-consuming queries a database will receive, you can precompute the results of those queries -- for example, replacing a 14-table join with a table that already contains the needed data.
That is different again. The two common reasons for that are:
Such that you need to build an additional file (or Materialised View) to service the slow queries. Yes, that is de-Normalising, and on a grand scale, but it is worse, it is a 100% copy of those fields.
If you love us? You can donate to us via Paypal or buy me a coffee so we can maintain and grow! Thank you!
Donate Us With

