I use ^$|^[^\s]+(\s+[^\s]+)*$ to achieve:
But how can I put the quantifiers to limit character count in between 6 - 20?
The following should pass
"" <-- (empty string)
"中文" <-- ( any character)
"A B" <-- (allow space in middle)
"hi! Hello There"
The following should fail
"A" <-- (less than 2 number of characters)
" AB" <-- (space at the start)
"AB " <-- (space at the end)
" AB "
"test test test test test test" <--- (more than 20 characters included spaces)
Thanks!
Trimming Whitespace You can easily trim unnecessary whitespace from the start and the end of a string or the lines in a text file by doing a regex search-and-replace. Search for ^[ \t]+ and replace with nothing to delete leading whitespace (spaces and tabs). Search for [ \t]+$ to trim trailing whitespace.
To match a character having special meaning in regex, you need to use a escape sequence prefix with a backslash ( \ ). E.g., \. matches "." ; regex \+ matches "+" ; and regex \( matches "(" . You also need to use regex \\ to match "\" (back-slash).
Whitespace character: \s. Non-whitespace character: \S.
Decimal digit character: \d \d matches any decimal digit. It is equivalent to the \p{Nd} regular expression pattern, which includes the standard decimal digits 0-9 as well as the decimal digits of a number of other character sets. If ECMAScript-compliant behavior is specified, \d is equivalent to [0-9].
You can use this regex:
^(?:\S.{4,18}\S)?$
How about such regex?
^$|^\S.{4,18}\S$
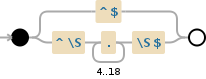
Debuggex Demo
If you love us? You can donate to us via Paypal or buy me a coffee so we can maintain and grow! Thank you!
Donate Us With


