Instead of using a split, I think it would be easier to simply execute a match and process all the found matches.
This expression will:
Regex: (?:^|,)(?=[^"]|(")?)"?((?(1)[^"]*|[^,"]*))"?(?=,|$)

Sample Text
123,2.99,AMO024,Title,"Description, more info",,123987564
ASP example using the non-java expression
Set regEx = New RegExp
regEx.Global = True
regEx.IgnoreCase = True
regEx.MultiLine = True
sourcestring = "your source string"
regEx.Pattern = "(?:^|,)(?=[^""]|("")?)""?((?(1)[^""]*|[^,""]*))""?(?=,|$)"
Set Matches = regEx.Execute(sourcestring)
For z = 0 to Matches.Count-1
results = results & "Matches(" & z & ") = " & chr(34) & Server.HTMLEncode(Matches(z)) & chr(34) & chr(13)
For zz = 0 to Matches(z).SubMatches.Count-1
results = results & "Matches(" & z & ").SubMatches(" & zz & ") = " & chr(34) & Server.HTMLEncode(Matches(z).SubMatches(zz)) & chr(34) & chr(13)
next
results=Left(results,Len(results)-1) & chr(13)
next
Response.Write "<pre>" & results
Matches using the non-java expression
Group 0 gets the entire substring which includes the comma
Group 1 gets the quote if it's used
Group 2 gets the value not including the comma
[0][0] = 123
[0][1] =
[0][2] = 123
[1][0] = ,2.99
[1][1] =
[1][2] = 2.99
[2][0] = ,AMO024
[2][1] =
[2][2] = AMO024
[3][0] = ,Title
[3][1] =
[3][2] = Title
[4][0] = ,"Description, more info"
[4][1] = "
[4][2] = Description, more info
[5][0] = ,
[5][1] =
[5][2] =
[6][0] = ,123987564
[6][1] =
[6][2] = 123987564
Worked on this for a bit and came up with this solution:
(?:,|\n|^)("(?:(?:"")*[^"]*)*"|[^",\n]*|(?:\n|$))
Try it out here!
This solution handles "nice" CSV data like
"a","b",c,"d",e,f,,"g"
0: "a"
1: "b"
2: c
3: "d"
4: e
5: f
6:
7: "g"
and uglier things like
"""test"" one",test' two,"""test"" 'three'","""test 'four'"""
0: """test"" one"
1: test' two
2: """test"" 'three'"
3: """test 'four'"""
Here's an explanation of how it works:
(?:,|\n|^) # all values must start at the beginning of the file,
# the end of the previous line, or at a comma
( # single capture group for ease of use; CSV can be either...
" # ...(A) a double quoted string, beginning with a double quote (")
(?: # character, containing any number (0+) of
(?:"")* # escaped double quotes (""), or
[^"]* # non-double quote characters
)* # in any order and any number of times
" # and ending with a double quote character
| # ...or (B) a non-quoted value
[^",\n]* # containing any number of characters which are not
# double quotes ("), commas (,), or newlines (\n)
| # ...or (C) a single newline or end-of-file character,
# used to capture empty values at the end of
(?:\n|$) # the file or at the ends of lines
)
I created this a few months ago for a project.
".+?"|[^"]+?(?=,)|(?<=,)[^"]+
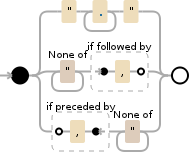
It works in C# and the Debuggex was happy when I selected Python and PCRE. Javascript doesn't recognize this form of Proceeded By ?<=....
For your values, it will create matches on
123
,2.99
,AMO024
,Title
"Description, more info"
,
,123987564
Note that anything in quotes doesn't have a leading comma, but attempting to match with a leading comma was required for the empty value use case. Once done, trim values as necessary.
I use RegexHero.Net to test my Regex.
I'm late to the party, but the following is the Regular Expression I use:
(?:,"|^")(""|[\w\W]*?)(?=",|"$)|(?:,(?!")|^(?!"))([^,]*?)(?=$|,)|(\r\n|\n)
This pattern has three capturing groups:
This pattern handles all of the following:
See this pattern in use.
If you have are using a more capable flavor of regex with named groups and lookbehinds, I prefer the following:
(?<quoted>(?<=,"|^")(?:""|[\w\W]*?)*(?=",|"$))|(?<normal>(?<=,(?!")|^(?!"))[^,]*?(?=(?<!")$|(?<!"),))|(?<eol>\r\n|\n)
See this pattern in use.
Edit
(?:^"|,")(""|[\w\W]*?)(?=",|"$)|(?:^(?!")|,(?!"))([^,]*?)(?=$|,)|(\r\n|\n)
This slightly modified pattern handles lines where the first column is empty as long as you are not using Javascript. For some reason Javascript will omit the second column with this pattern. I was unable to correctly handle this edge-case.
I needed this answer too, but I found the answers, while informative, a little hard to follow and replicate for other languages. Here is the simplest expression I came up with for a single column out of the CSV line. I am not splitting. I'm building a regex to match a column out of the CSV so I'm not splitting the line:
("([^"]*)"|[^,]*)(,|$)
This matches a single column from the CSV line. The first portion "([^"]*)" of the expression is to match a quoted entry, the second part [^,]* is to match a non-quoted entry. Then either followed by a , or end of line $.
And the accompanying debuggex to test out the expression.
https://www.debuggex.com/r/s4z_Qi2gZiyzpAhx
I personally tried many RegEx expressions without having found the perfect one that match all cases.
I think that regular expressions is hard to configure properly to match all cases properly. Although few persons will not like the namespace (and I was part of them), I propose something that is part of the .Net framework and give me proper results all the times in all cases (mainly managing every double quotes cases very well):
Microsoft.VisualBasic.FileIO.TextFieldParser
Found it here: StackOverflow
Example of usage:
TextReader textReader = new StringReader(simBaseCaseScenario.GetSimStudy().Study.FilesToDeleteWhenComplete);
Microsoft.VisualBasic.FileIO.TextFieldParser textFieldParser = new TextFieldParser(textReader);
textFieldParser.SetDelimiters(new string[] { ";" });
string[] fields = textFieldParser.ReadFields();
foreach (string path in fields)
{
...
Hope it could help.
If you love us? You can donate to us via Paypal or buy me a coffee so we can maintain and grow! Thank you!
Donate Us With