I set up a complex regex to extract data from a page of text. For some reason the order of the alternation is not what I expect. A simple example would be:
((13th|(Executive |Residential)|((\w+) ){1,3})Floor)
Put simply I am trying to either get a floor number, a known named floor and, as a back-up, I capture 1-3 unknown words followed by floor just in case to review later (I in fact use a groupname to identify this but didn't want to confuse the issue)
The issue is if the string is
on the 13th Floor
I don't get 13th Floor I get on the 13th Floor which seems to indicate it is matching the 3rd alternation. I'd have expected it to match 13th Floor. I set this up specifically (or so I thought) to prioritize the types of matches and leave the vague ones for last only if the others are missed. I guess they weren't kidding when they said Regex is greedy but I am unclear how to set this up to be 'greedy' and behave the way I want.
Well an automaton is worth a 1000 words:
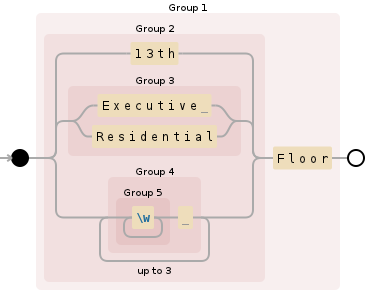
play with it
Your problem is that you're using a greedy \w+ sub-regex in your alternation. Because as @rigderunner is stating in his comment, a NFA is matching the longest leftmost substring, the \w+ will always match anything that comes before Floor, whether it is a series of words, or 13th or Executive or Residential or the three of them. The parenthesis are not changing how the alternation behaves.
So the worst case scenario it matches that you don't want it to match is:
xxxx yyyy zzz tttt Floor
The problem with your regex is that you expect to do something that actual regular expressions can't do: you're expecting it to match words if the alternatives did not work out. Because a regular language can't keep track of status, regular regex can't express this.
I'm actually not sure if using some kind of look ahead could help you do this in one regex, and even if you can, you'll end up with a very complicated, unreadable and maybe even not efficient regex.
So you may prefer to use two regex instead, and get the groups from the second regex in case the first one failed:
((13th|Executive|Residential) +Floor)
and if there's no match
((\w+ +){1:3}Floor)
N.B.: to avoid repeating myself, please have a look at that other answer where I give a list of interesting resources lecturing on regex and NFA. That will help you understand how regex actually works.
First, here is your regex in free-spacing mode:
tidied = re.compile(r"""
( # $1: ...
( # $2: One ... from 3 alternatives.
13th # Either a1of3.
| ( # Or a2of3 $3: One ... from 2 alternatives.
Executive[ ] # Either a1of2.
| Residential # Or a2of2.
) # End $3: One ... from 2 alternatives.
| ( # Or a3of3 $4: Last match from 1 to 3 ...
(\w+) # $5: ...
[ ] #
){1,3} # End $4: Last match from 1 to 3 ...
) # End $2: One ... from 3 alternatives.
Floor #
) # End $1: ...
""", re.VERBOSE)
Note that the above pattern has extra parentheses that are having no effect. Here is a simplified expression which is functionally equivalent:
tidied = re.compile(r"""
( # $1: One ... from 4 alternatives.
13th # Either a1of4.
| Executive[ ] # Or a2of4.
| Residential # Or a3of4.
| ( # Or a4of4 $2: Last match from 1 to 3 ...
(\w+) # $3: ...
[ ] #
){1,3} # End $2: Last match from 1 to 3 ...
) # End $1: One ... from 4 alternatives.
Floor #
""", re.VERBOSE)
There are effectively four grouped alternatives preceding the required word: Floor. The first three alternatives are each one word only, but the fourth option matches three words. An NFA regex engine works from left to right and always attempts to find the longest leftmost match. In this case, as the regex marches through the regex one character at a time, it tests all four options at each character position. Since the fourth option can always match two words ahead of the other three, it will always match first (assuming there are three words preceding Floor in the given text.). If there are NOT three words preceding Floor, then one of the first three alternatives can match.
Note also that there is no required space following the 13th and Residential alternatives, thus it will only ever match when presented text having the concatenated text: ResidentialFloor or 13thFloor.
If you love us? You can donate to us via Paypal or buy me a coffee so we can maintain and grow! Thank you!
Donate Us With


