I am wondering what happens when there are multiple Non-PK columns in a table. I've read this example: http://johnsanda.blogspot.co.uk/2012/10/why-i-am-ready-to-move-to-cql-for.html
Which shows that with single column:
CREATE TABLE raw_metrics (
schedule_id int,
time timestamp,
value double,
PRIMARY KEY (schedule_id, time)
);
We get:
Now I wonder what happens when we have two columns:
CREATE TABLE raw_metrics (
schedule_id int,
time timestamp,
value1 double,
value2 int,
PRIMARY KEY (schedule_id, time)
);
Are we going to end up with something like:
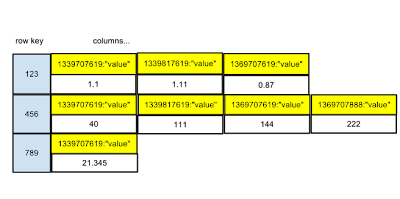
row key columns...
123 1339707619:"value1" | 1339707679:"value2" | 1339707784:"value2"
...
or rather:
row key columns...
123 1339707619:"value1":"value2" | 1339707679:"value1":"value2" | 1339707784:"value1""value2"
...
etc. I guess what I am asking is if this is going to be a sparse table given that I only insert "value1" or "value2" at a time.
In such situations if I want to store more columns (one per each type, eg. double, int, date, etc) would it be better perhaps to have separate tables rather than storing everything in a single table?
This post might help in explaining what is happening when composite keys are created: Cassandra Composite Columns - How are CompositeTypes chosen?
So essentially the table will look in the following way:
row key columns...
123 1339707619:"value1" | 1339707679:"value2" | 1339707784:"value2"
See also reference to secondary indexes: http://wiki.apache.org/cassandra/SecondaryIndexes
If you love us? You can donate to us via Paypal or buy me a coffee so we can maintain and grow! Thank you!
Donate Us With

