I am seeing that the ToTensor is always at the end https://github.com/pytorch/examples/blob/main/imagenet/main.py:
train_dataset = datasets.ImageFolder(
traindir,
transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
]))
val_dataset = datasets.ImageFolder(
valdir,
transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
]))
other for mini-imagenet:
train_data_transform = Compose([
# ToPILImage(),
RandomCrop(size, padding=8),
# decided 8 due to https://datascience.stackexchange.com/questions/116201/when-to-use-padding-when-randomly-cropping-images-in-deep-learning
ColorJitter(brightness=0.4, contrast=0.4, saturation=0.4),
RandomHorizontalFlip(),
ToTensor(),
normalize,
])
test_data_transform = transforms.Compose([
transforms.Resize((size, size)),
transforms.ToTensor(),
transforms.Normalize(mean=mean,
std=std),
])
validation_data_transform = test_data_transform
is there a reason for this? What happens if we do the ToTensor (or ToTensor and Normalize) first?
One reason why people usually use PIL format instead of tensor to perform image preprocessing is related to the resizing algorithms and especially downsizing. As pointed out in this paper,
The Lanczos, bicubic, and bilinear implementations by PIL (top row) adjust the antialiasing filter width by the downsampling factor (marked as ). Other implementations (including those used for PyTorch-FID and TensorFlow-FID) use fixed filter widths, introducing aliasing artifacts and resemble naive nearest subsampling.
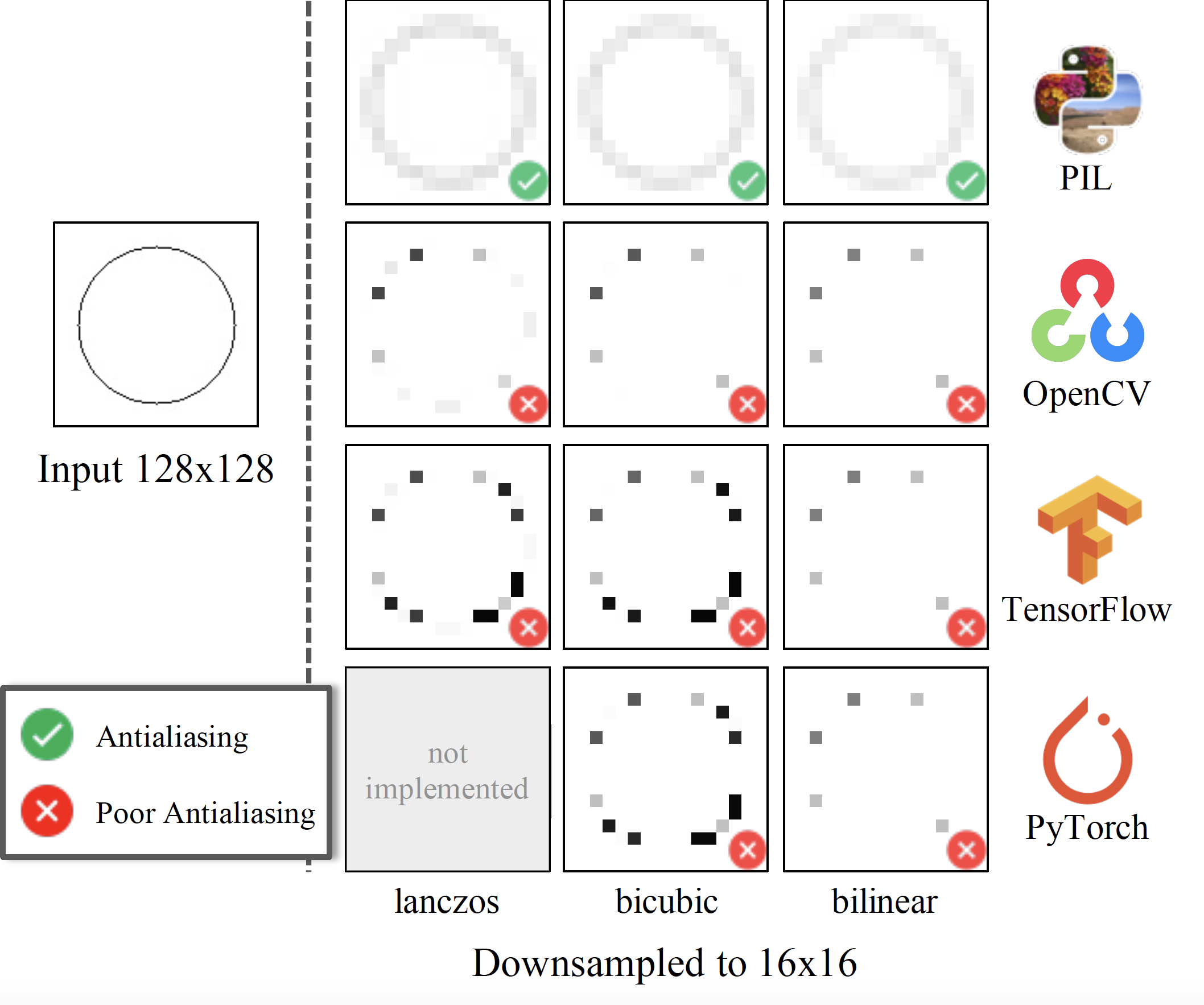
image source: clean-fid official github repo
Despite that torchvision.transforms.Resize now supports antialias option, as per the documentation, it is only reducing the gap between the tensor outputs and PIL outputs to some extent. Another reason may be related to the reproducibility and portability, i.e. to have a universal preprocessing pipeline.
 answered Oct 20 '25 11:10
answered Oct 20 '25 11:10
If you love us? You can donate to us via Paypal or buy me a coffee so we can maintain and grow! Thank you!
Donate Us With
