I need to find a regex to match each sentence whether it's following Title Case or not (first letter of each word of the sentence should be in upper case and the words can can contain special characters as well).
To match a character having special meaning in regex, you need to use a escape sequence prefix with a backslash ( \ ). E.g., \. matches "." ; regex \+ matches "+" ; and regex \( matches "(" . You also need to use regex \\ to match "\" (back-slash).
The word boundary \b matches positions where one side is a word character (usually a letter, digit or underscore—but see below for variations across engines) and the other side is not a word character (for instance, it may be the beginning of the string or a space character).
By default, the '. ' dot character in a regular expression matches a single character without regard to what character it is. The matched character can be an alphabet, a number or, any special character.
How do you ignore something in regex? To match any character except a list of excluded characters, put the excluded charaters between [^ and ] . The caret ^ must immediately follow the [ or else it stands for just itself.
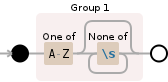
([A-Z][^\s]*)
Debuggex Demo
Description
1st Capturing group ([A-Z][^\s]*)
[A-Z] match a single character present in the list below
A-Z a single character in the range between A and Z (case sensitive)
[^\s]* match a single character not present in the list below
Quantifier: * Between zero and unlimited times, as many times as possible, giving back as needed [greedy]
\s match any white space character [\r\n\t\f ]
g modifier: global. All matches (don't return on first match)
^(?:[A-Z][^\s]*\s?)+$

Debuggex Demo
Description
^ assert position at start of the string
(?:[A-Z][^\s]*\s?)+ Non-capturing group
Quantifier: + Between one and unlimited times, as many times as possible, giving back as needed [greedy]
[A-Z] match a single character present in the list below
A-Z a single character in the range between A and Z (case sensitive)
[^\s]* match a single character not present in the list below
Quantifier: * Between zero and unlimited times, as many times as possible, giving back as needed [greedy]
\s match any white space character [\r\n\t\f ]
\s? match any white space character [\r\n\t\f ]
Quantifier: ? Between zero and one time, as many times as possible, giving back as needed [greedy]
$ assert position at end of the string
This works for me:
It groups all the Title Case Words Together. Useful for matching, say, a list of People's Names
(?:[A-Z][a-z]+\s?)+
Python Examples:
# Example 1
text = "WANTED"
re.findall(r'(?:[A-Z][a-z]+\s?)+', text, re.M)
>>> [] # Does not pass
# Example 2
text = "This is a Test. This Is Another Test"
re.findall(r'(?:[A-Z][a-z]+\s?)+', text, re.M)
>>> ['This ', 'Test', 'This Is Another Test'] # Group of Title Case Phrases
If you only want a list of all the individual Title Case words use this:
'(?:[A-Z][a-z]+)'
Python Example:
# Example 1
import re
text = "This is a Test. This Is Another Test"
re.findall(r'(?:[A-Z][a-z]+)', text, re.M)
>>> ['This', 'Test', 'This', 'Is', 'Another', 'Test'] # All Title Cased words
If you love us? You can donate to us via Paypal or buy me a coffee so we can maintain and grow! Thank you!
Donate Us With


