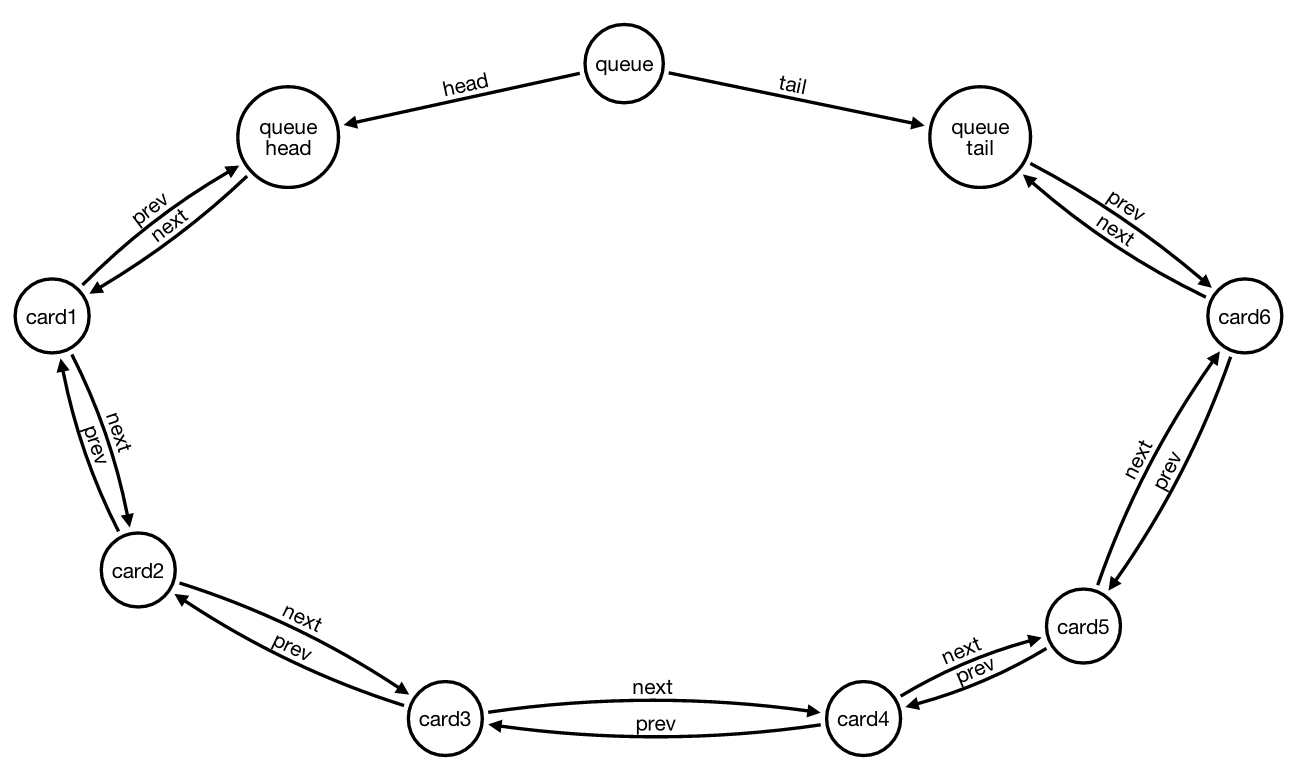
In my Neo4J database I have a series of queues of cards implemented via doubly-linked lists. The data structure is displayed in the following figure (SVG graph of queue generated using Alistair Jones' Arrows online tool):

Since these are queues, I always add new items from the TAIL of the queue. I know that the double relationships (next/previous) is not necessary, but they simplify traversal in both direction, so I prefer to have them.
This is the query that I am using to insert a new "card":
MATCH (currentList:List)-[currentTailRel:TailCard]->(currentTail:Card) WHERE ID(currentList) = {{LIST_ID}}
CREATE (currentList)-[newTailRel:TailCard]->(newCard:Card { title: {{TITLE}}, description: {{DESCRIPTION}} })
CREATE (newCard)-[newPrevRel:PreviousCard]->(currentTail)
CREATE (currentTail)-[newNextRel:NextCard]->(newCard)
DELETE currentTailRel
WITH count(newCard) as countNewCard
WHERE countNewCard = 0
MATCH (emptyList:List)-[fakeTailRel:TailCard]->(emptyList),
(emptyList)-[fakeHeadRel:HeadCard]->(emptyList)
WHERE ID(emptyList) = {{LIST_ID}}
WITH emptyList, fakeTailRel, fakeHeadRel
CREATE (emptyList)-[:TailCard]->(newCard:Card { title: {{TITLE}}, description: {{DESCRIPTION}} })
CREATE (emptyList)-[:HeadCard]->(newCard)
DELETE fakeTailRel, fakeHeadRel
RETURN true
The query can be broken in two parts. In the first part:
MATCH (currentList:List)-[currentTailRel:TailCard]->(currentTail:Card) WHERE ID(currentList) = {{LIST_ID}}
CREATE (currentList)-[newTailRel:TailCard]->(newCard:Card { title: {{TITLE}}, description: {{DESCRIPTION}} })
CREATE (newCard)-[newPrevRel:PreviousCard]->(currentTail)
CREATE (currentTail)-[newNextRel:NextCard]->(newCard)
DELETE currentTailRel
I handle the general case of adding a card to a queue that already has other cards. In the second part:
WITH count(newCard) as countNewCard
WHERE countNewCard = 0
MATCH (emptyList:List)-[fakeTailRel:TailCard]->(emptyList),
(emptyList)-[fakeHeadRel:HeadCard]->(emptyList)
WHERE ID(emptyList) = {{LIST_ID}}
WITH emptyList, fakeTailRel, fakeHeadRel
CREATE (emptyList)-[:TailCard]->(newCard:Card { title: {{TITLE}}, description: {{DESCRIPTION}} })
CREATE (emptyList)-[:HeadCard]->(newCard)
DELETE fakeTailRel, fakeHeadRel
RETURN true
I handle the case in which there are no cards in the queue. In that case the (emptyList) node has two relationships of type HeadCard and TailCard pointing to itself (I call them fake tail and fake head).
This seems to be working. Being a noob at this though, I have a feeling that I am overthinking things and that there might be a more elegant and straightforward way to achieve this. One thing I'd like to understand how to do in a better/simpler way, for example, is how to separate the two subqueries. I'd also like to be able to return the newly created node in both cases, if possible.
Here is how I am removing nodes from the queue. I never want to simply delete nodes, I'd rather add them to an archive node so that, in case of need, they can be recovered. I have identified these cases:
When the node to be archived is in the middle of the queue
// archive a node in the middle of a doubly-linked list
MATCH (before:Card)-[n1:NextCard]->(middle:Card)-[n2:NextCard]->(after:Card)
WHERE ID(middle)=48
CREATE (before)-[:NextCard]->(after)
CREATE (after)-[:PreviousCard]->(before)
WITH middle, before, after
MATCH (middle)-[r]-(n)
DELETE r
WITH middle, before, after
MATCH (before)<-[:NextCard*]-(c:Card)<-[:HeadCard]-(l:List)<-[:NextList*]-(fl:List)<-[:HeadList]-(p:Project)-[:ArchiveList]->(archive:List)
CREATE (archive)-[r:Archived { archivedOn : timestamp() }]->(middle)
RETURN middle
When the node to be archived is the head of the queue
// archive the head node of a doubly-linked list
MATCH (list:List)-[h1:HeadCard]->(head:Card)-[n1:NextCard]->(second:Card)
WHERE ID(head)=48
CREATE (list)-[:HeadCard]->(second)
WITH head, list
MATCH (head)-[r]-(n)
DELETE r
WITH head, list
MATCH (list)<-[:NextList*]-(fl:List)<-[:HeadList]-(p:Project)-[:ArchiveList]->(archive:List)
CREATE (archive)-[r:Archived { archivedOn : timestamp() }]->(head)
RETURN head
When the node to be archived is the tail of the queue
// archive the tail node of a doubly-linked list
MATCH (list:List)-[t1:TailCard]->(tail:Card)-[p1:PreviousCard]->(nextToLast:Card)
WHERE ID(tail)=48
CREATE (list)-[:TailCard]->(nextToLast)
WITH tail, list
MATCH (tail)-[r]-(n)
DELETE r
WITH tail, list
MATCH (list)<-[:NextList*]-(fl:List)<-[:HeadList]-(p:Project)-[:ArchiveList]->(archive:List)
CREATE (archive)-[r:Archived { archivedOn : timestamp() }]->(tail)
RETURN tail
When the node to be archived is the only node in the queue
// archive the one and only node in the doubly-linked list
MATCH (list:List)-[tc:TailCard]->(only:Card)<-[hc:HeadCard]-(list:List)
WHERE ID(only)=48
CREATE (list)-[:TailCard]->(list)
CREATE (list)-[:HeadCard]->(list)
WITH only, list
MATCH (only)-[r]-(n)
DELETE r
WITH only, list
MATCH (list)<-[:NextList*]-(fl:List)<-[:HeadList]-(p:Project)-[:ArchiveList]->(archive:List)
CREATE (archive)-[r:Archived { archivedOn : timestamp() }]->(only)
RETURN only
I have tried in many ways to combine the following cypher queries into one, using WITH statements, but I was unsuccessful. My current plan is to run all 4 queries one after the other. Only one will actually do something (i.e. archive the node).
Any suggestions to make this better and more streamlined? I am even open to restructuring the data structure since this is a sandbox project that I created for myself to learn Angular and Neo4J, so the ultimate goal is to learn how to do thing better :)
Maybe the data structure itself could be improved? Given how complicated is to insert/archive a node at the end of the queue, I can only imagine how hard is going to be to move elements in the queue (one of the requirements of my self project is to be able to reorder elements in the queue whenever needed).
Still working on trying to combine those 4 queries. I got this together:
MATCH (theCard:Card) WHERE ID(theCard)=22
OPTIONAL MATCH (before:Card)-[btc:NEXT_CARD]->(theCard:Card)-[tca:NEXT_CARD]->(after:Card)
OPTIONAL MATCH (listOfOne:List)-[lootc:TAIL_CARD]->(theCard:Card)<-[tcloo:HEAD_CARD]-(listOfOne:List)
OPTIONAL MATCH (listToHead:List)-[lthtc:HEAD_CARD]->(theCard:Card)-[tcs:NEXT_CARD]->(second:Card)
OPTIONAL MATCH (listToTail:List)-[ltttc:TAIL_CARD]->(theCard:Card)-[tcntl:PREV_CARD]->(nextToLast:Card)
RETURN theCard, before, btc, tca, after, listOfOne, lootc, tcloo, listToHead, lthtc, tcs, second, listToTail, ltttc, tcntl, nextToLast
which is return NULLs when something is not found, and nodes/relationship when something is found. I thought this could be a good starting point, so I added the following:
MATCH (theCard:Card) WHERE ID(theCard)=22
OPTIONAL MATCH (before:Card)-[btc:NEXT_CARD]->(theCard:Card)-[tca:NEXT_CARD]->(after:Card)
OPTIONAL MATCH (listOfOne:List)-[lootc:TAIL_CARD]->(theCard:Card)<-[tcloo:HEAD_CARD]-(listOfOne:List)
OPTIONAL MATCH (listToHead:List)-[lthtc:HEAD_CARD]->(theCard:Card)-[tcs:NEXT_CARD]->(second:Card)
OPTIONAL MATCH (listToTail:List)-[ltttc:TAIL_CARD]->(theCard:Card)-[tcntl:PREV_CARD]->(nextToLast:Card)
WITH theCard,
CASE WHEN before IS NULL THEN [] ELSE COLLECT(before) END AS beforeList,
before, btc, tca, after,
listOfOne, lootc, tcloo, listToHead, lthtc, tcs, second, listToTail, ltttc, tcntl, nextToLast
FOREACH (value IN beforeList | CREATE (before)-[:NEXT_CARD]->(after))
FOREACH (value IN beforeList | CREATE (after)-[:PREV_CARD]->(before))
FOREACH (value IN beforeList | DELETE btc)
FOREACH (value IN beforeList | DELETE tca)
RETURN theCard
When I executed this (with an ID chosen to make before=NULL, the fan of my laptop start spinning like crazy, the query never returns and eventually the neo4j browser says that it has lost connection with the server. The only way to end the query is to stop the server.
So I changed the query to the simpler:
MATCH (theCard:Card) WHERE ID(theCard)=22
OPTIONAL MATCH (before:Card)-[btc:NEXT_CARD]->(theCard:Card)-[tca:NEXT_CARD]->(after:Card)
OPTIONAL MATCH (listOfOne:List)-[lootc:TAIL_CARD]->(theCard:Card)<-[tcloo:HEAD_CARD]-(listOfOne:List)
OPTIONAL MATCH (listToHead:List)-[lthtc:HEAD_CARD]->(theCard:Card)-[tcs:NEXT_CARD]->(second:Card)
OPTIONAL MATCH (listToTail:List)-[ltttc:TAIL_CARD]->(theCard:Card)-[tcntl:PREV_CARD]->(nextToLast:Card)
RETURN theCard,
CASE WHEN before IS NULL THEN [] ELSE COLLECT(before) END AS beforeList,
before, btc, tca, after,
listOfOne, lootc, tcloo, listToHead, lthtc, tcs, second, listToTail, ltttc, tcntl, nextToLast
And I still end up in an infinite loop or something...
So I guess the line CASE WHEN before IS NULL THEN [] ELSE COLLECT(before) END AS beforeList was not a good idea... Any suggestions on how to proceed from here? Am I on the wrong path?
Finally, after much research, I found a way to write a single query that takes care of all possible scenarios. I don't know if this is the best way to achieve what I am trying to achieve, but it seems elegant and compact enough to me. What do you think?
// first let's get a hold of the card we want to archive
MATCH (theCard:Card) WHERE ID(theCard)=44
// next, let's get a hold of the correspondent archive list node, since we need to move the card in that list
OPTIONAL MATCH (theCard)<-[:NEXT_CARD|HEAD_CARD*]-(theList:List)<-[:NEXT_LIST|HEAD_LIST*]-(theProject:Project)-[:ARCHIVE_LIST]->(theArchive:List)
// let's check if we are in the case where the card to be archived is in the middle of a list
OPTIONAL MATCH (before:Card)-[btc:NEXT_CARD]->(theCard:Card)-[tca:NEXT_CARD]->(after:Card)
OPTIONAL MATCH (next:Card)-[ntc:PREV_CARD]->(theCard:Card)-[tcp:PREV_CARD]->(previous:Card)
// let's check if the card to be archived is the only card in the list
OPTIONAL MATCH (listOfOne:List)-[lootc:TAIL_CARD]->(theCard:Card)<-[tcloo:HEAD_CARD]-(listOfOne:List)
// let's check if the card to be archived is at the head of the list
OPTIONAL MATCH (listToHead:List)-[lthtc:HEAD_CARD]->(theCard:Card)-[tcs:NEXT_CARD]->(second:Card)-[stc:PREV_CARD]->(theCard:Card)
// let's check if the card to be archived is at the tail of the list
OPTIONAL MATCH (listToTail:List)-[ltttc:TAIL_CARD]->(theCard:Card)-[tcntl:PREV_CARD]->(nextToLast:Card)-[ntltc:NEXT_CARD]->(theCard:Card)
WITH
theCard, theList, theProject, theArchive,
CASE WHEN theArchive IS NULL THEN [] ELSE [(theArchive)] END AS archives,
CASE WHEN before IS NULL THEN [] ELSE [(before)] END AS befores,
before, btc, tca, after,
CASE WHEN next IS NULL THEN [] ELSE [(next)] END AS nexts,
next, ntc, tcp, previous,
CASE WHEN listOfOne IS NULL THEN [] ELSE [(listOfOne)] END AS listsOfOne,
listOfOne, lootc, tcloo,
CASE WHEN listToHead IS NULL THEN [] ELSE [(listToHead)] END AS listsToHead,
listToHead, lthtc, tcs, second, stc,
CASE WHEN listToTail IS NULL THEN [] ELSE [(listToTail)] END AS listsToTail,
listToTail, ltttc, tcntl, nextToLast, ntltc
// let's handle the case in which the archived card was in the middle of a list
FOREACH (value IN befores |
CREATE (before)-[:NEXT_CARD]->(after)
CREATE (after)-[:PREV_CARD]->(before)
DELETE btc, tca)
FOREACH (value IN nexts | DELETE ntc, tcp)
// let's handle the case in which the archived card was the one and only card in the list
FOREACH (value IN listsOfOne |
CREATE (listOfOne)-[:HEAD_CARD]->(listOfOne)
CREATE (listOfOne)-[:TAIL_CARD]->(listOfOne)
DELETE lootc, tcloo)
// let's handle the case in which the archived card was at the head of the list
FOREACH (value IN listsToHead |
CREATE (listToHead)-[:HEAD_CARD]->(second)
DELETE lthtc, tcs, stc)
// let's handle the case in which the archived card was at the tail of the list
FOREACH (value IN listsToTail |
CREATE (listToTail)-[:TAIL_CARD]->(nextToLast)
DELETE ltttc, tcntl, ntltc)
// finally, let's move the card in the archive
// first get a hold of the archive list to which we want to add the card
WITH
theCard,
theArchive
// first get a hold of the list to which we want to add the new card
OPTIONAL MATCH (theArchive)-[tact:TAIL_CARD]->(currentTail:Card)
// check if the list is empty
OPTIONAL MATCH (theArchive)-[tata1:TAIL_CARD]->(theArchive)-[tata2:HEAD_CARD]->(theArchive)
WITH
theArchive, theCard,
CASE WHEN currentTail IS NULL THEN [] ELSE [(currentTail)] END AS currentTails,
currentTail, tact,
CASE WHEN tata1 IS NULL THEN [] ELSE [(theArchive)] END AS emptyLists,
tata1, tata2
// handle the case in which the list already had at least one card
FOREACH (value IN currentTails |
CREATE (theArchive)-[:TAIL_CARD]->(theCard)
CREATE (theCard)-[:PREV_CARD]->(currentTail)
CREATE (currentTail)-[:NEXT_CARD]->(theCard)
DELETE tact)
// handle the case in which the list was empty
FOREACH (value IN emptyLists |
CREATE (theArchive)-[:TAIL_CARD]->(theCard)
CREATE (theArchive)-[:HEAD_CARD]->(theCard)
DELETE tata1, tata2)
RETURN theCard
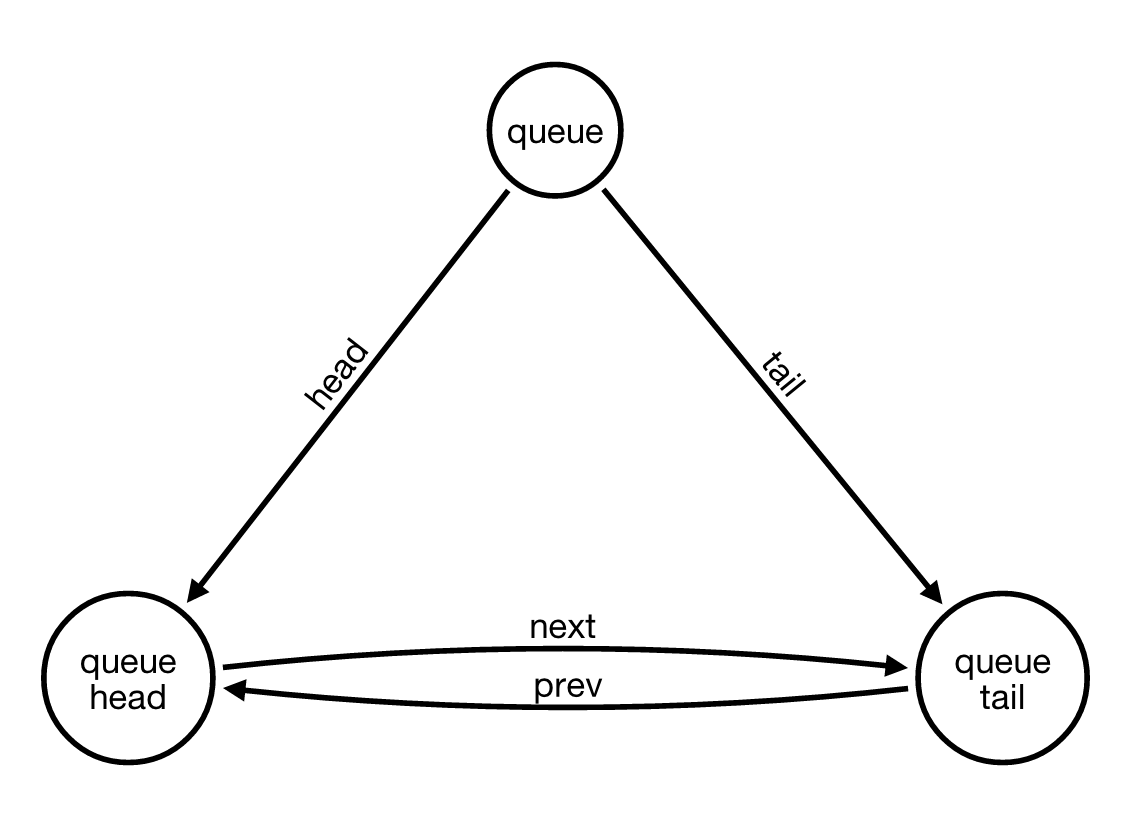
Following Wes advice I decided to change the way each of the queues in my application was handled, adding two extra nodes, the head and the tail.
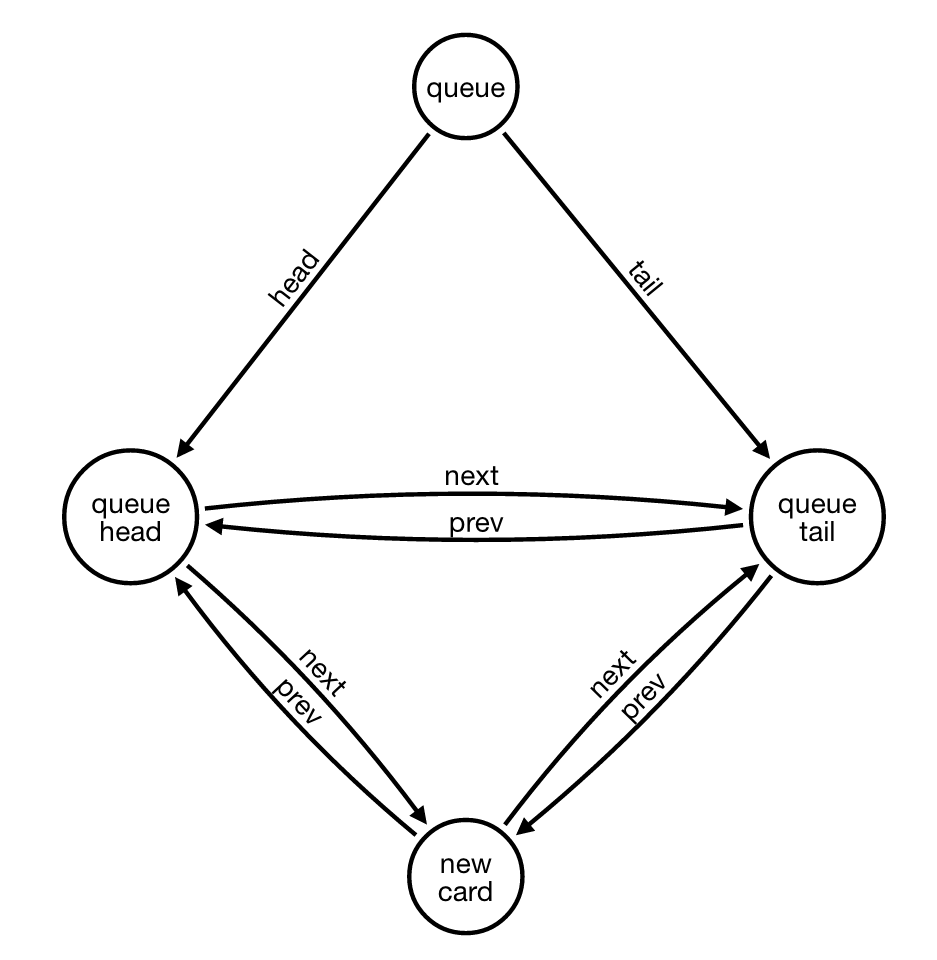
Moving the concepts of head and tail from simple relationships to nodes allows to have a single case when inserting a new card. Even in the special case of an empty queue…
all we have to do to add a new card to the tail of the queue is:
which translates into the following cypher query:
MATCH (theList:List)-[tlt:TAIL_CARD]->(tail)-[tp:PREV_CARD]->(previous)-[pt:NEXT_CARD]->(tail)
WHERE ID(theList)={{listId}}
WITH theList, tail, tp, pt, previous
CREATE (newCard:Card { title: "Card Title", description: "" })
CREATE (tail)-[:PREV_CARD]->(newCard)-[:NEXT_CARD]->(tail)
CREATE (newCard)-[:PREV_CARD]->(previous)-[:NEXT_CARD]->(newCard)
DELETE tp,pt
RETURN newCard
Now let's reconsider the use case in which we want to archive a card. Let's review the architecture:
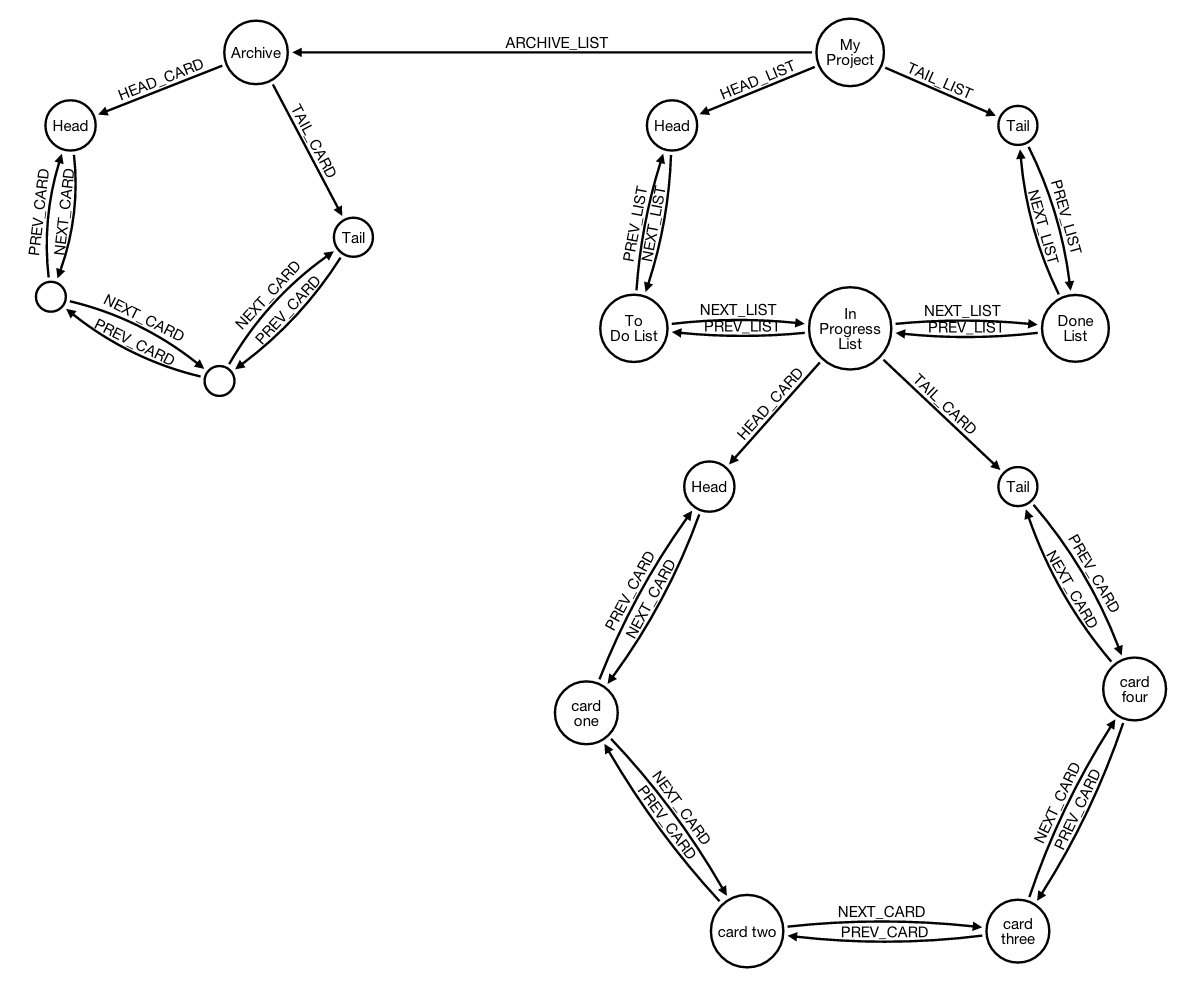
We have:
In the previous queue architecture I had 4 different scenarios, depending in whether the card to be archived was the head, the tail, or a card in between or if it was the last card left in the quee.
Now, with the introduction of the head and tail nodes, there is only one scenario, because the head and the tail node are there to stay, even in the case in which the queue is empty:
The resulting cypher query can be subdivided in three distinct parts. The first part is in charge of finding (theArchive) node, given the ID of (theCard) node:
MATCH (theCard)<-[:NEXT_CARD|HEAD_CARD*]-(l:List)<-[:NEXT_LIST*]-(h)<-[:HEAD_LIST]-(p:Project)-[:ARCHIVE]->(theArchive:Archive)
WHERE ID(theCard)={{cardId}}
Next, we execute the logic that I described few lines earlier:
WITH theCard, theArchive
MATCH (previous)-[ptc:NEXT_CARD]->(theCard)-[tcn:NEXT_CARD]->(next)-[ntc:PREV_CARD]->(theCard)-[tcp:PREV_CARD]->(previous)
WITH theCard, theArchive, previous, next, ptc, tcn, ntc, tcp
CREATE (previous)-[:NEXT_CARD]->(next)-[:PREV_CARD]->(previous)
DELETE ptc, tcn, ntc, tcp
Finally, we insert (theCard) at the tail of the archive queue:
WITH theCard, theArchive
MATCH (theArchive)-[tat:TAIL_CARD]->(archiveTail)-[tp:PREV_CARD]->(archivePrevious)-[pt:NEXT_CARD]->(archiveTail)
WITH theCard, theArchive, archiveTail, tp, pt, archivePrevious
CREATE (archiveTail)-[:PREV_CARD]->(theCard)-[:NEXT_CARD]->(archiveTail)
CREATE (theCard)-[:PREV_CARD]->(archivePrevious)-[:NEXT_CARD]->(theCard)
DELETE tp,pt
RETURN theCard
I hope you find this last edit interesting as I found working through this exercise. I want to thank again Wes for his remote help (via Twitter and Stack Overflow) in this interesting (at least to me) experiment.
A nice problem--doubly-linked lists in the graph. I recently worked on a similar concept where I needed to keep track of a list, but tried to come up with a way to avoid the difficulties of needing to know how to handle the end of the list edge cases. The result of my effort was this graph gist about skip lists in cypher.
Translated to a doubly-linked list, this would look like:
CREATE
(head:Head),
(tail:Tail),
(head)-[:NEXT]->(tail),
(tail)-[:PREV]->(head),
(a:Archive)-[:NEXT]->(:ArchiveTail)-[:PREV]->(a);
; // we need something to start at, and an archive list
Then you could queue nodes with the simple:
MATCH (tail:Tail)-[p:PREV]->(prev),
(tail)<-[n:NEXT]-(prev)
CREATE (new {text:"new card"})<-[:NEXT]-(prev),
(new)-[:PREV]->(prev),
(new)<-[:PREV]-(tail),
(new)-[:NEXT]->(tail)
DELETE p, n
And archive nodes with the fairly simple:
MATCH (toArchive)-[nn:NEXT]->(next),
(toArchive)<-[np:PREV]-(next),
(toArchive)<-[pn:NEXT]-(prev),
(toArchive)-[pp:PREV]->(prev)
WHERE toArchive.text = "new card 2"
CREATE (prev)-[:NEXT]->(next)-[:PREV]->(prev)
DELETE nn, np, pn, pp
WITH toArchive
MATCH (archive:Archive)-[n:NEXT]->(first)-[p:PREV]->(archive)
CREATE (archive)-[:NEXT]->(toArchive)<-[:PREV]-(first),
(archive)<-[:PREV]-(toArchive)-[:NEXT]->(first)
DELETE n, p
Your use cases are actually much easier than the skip list algorithmically, because you avoid most needs for varlength paths by keeping the tail to queue cards to the end directly. Hopefully others implementing similar ideas will find your SO question useful.
If you love us? You can donate to us via Paypal or buy me a coffee so we can maintain and grow! Thank you!
Donate Us With

