I'd like to fanout/chain/replicate an Input AWS Kinesis stream To N new Kinesis streams, So that each record written to the input Kinesis will appear in each of the N streams.
Is there an AWS service or an open source solution?
I prefer not to write code to do that if there's a ready-made solution. AWS Kinesis firehose is a no solution because it can't output to kinesis. Perhaps a AWS Lambda solution if that won't be too expensive to run?
In Amazon Kinesis Data Streams, you can build consumers that use a feature called enhanced fan-out. This feature enables consumers to receive records from a stream with throughput of up to 2 MB of data per second per shard.
You can delete a stream with the Kinesis Data Streams console, or programmatically.
Enhanced fan-out allows developers to scale up the number of stream consumers (applications reading data from a stream in real-time) by offering each stream consumer its own read throughput.
Therefore, operations that are throttled might not be ingested into the Kinesis data stream. This can result in a breach of stream limits and throttling without any metric indications. When there are failed records that aren't able to enter the Kinesis data stream, the stream throttles.
There are two ways you could accomplish fan-out of an Amazon Kinesis stream:
Option 1: Using Amazon Kinesis Analytics to fan-out
You can use Amazon Kinesis Analytics to generate a new stream from an existing stream.
From the Amazon Kinesis Analytics documentation:
Amazon Kinesis Analytics applications continuously read and process streaming data in real-time. You write application code using SQL to process the incoming streaming data and produce output. Then, Amazon Kinesis Analytics writes the output to a configured destination.
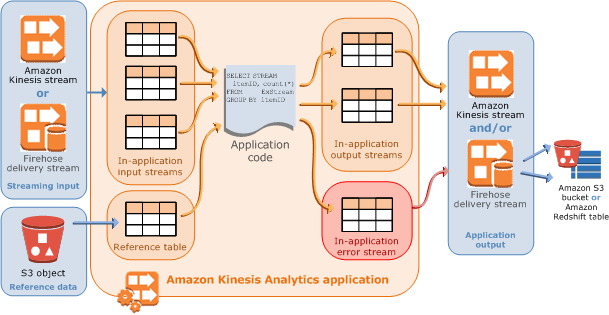
Fan-out is mentioned in the Application Code section:
You can also write SQL queries that run independent of each other. For example, you can write two SQL statements that query the same in-application stream, but send output into different in-applications streams.
I managed to implement this as follows:
The Amazon Kinesis Analytics SQL application looks like this:
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM"
(log VARCHAR(16));
CREATE OR REPLACE PUMP "COPY_PUMP1" AS
INSERT INTO "DESTINATION_SQL_STREAM"
SELECT STREAM "log" FROM "SOURCE_SQL_STREAM_001";
This code creates a pump (think of it as a continual select statement) that selects from the input stream and outputs to the output1 stream. I created another identical application that outputs to the output2 stream.
To test, I sent data to the input stream:
#!/usr/bin/env python
import json, time
from boto import kinesis
kinesis = kinesis.connect_to_region("us-west-2")
i = 0
while True:
data={}
data['log'] = 'Record ' + str(i)
i += 1
print data
kinesis.put_record("input", json.dumps(data), "key")
time.sleep(2)
I let it run for a while, then displayed the output using this code:
from boto import kinesis
kinesis = kinesis.connect_to_region("us-west-2")
iterator = kinesis.get_shard_iterator('output1', 'shardId-000000000000', 'TRIM_HORIZON')['ShardIterator']
records = kinesis.get_records(iterator, 5)
print [r['Data'] for r in records['Records']]
The output was:
[u'{"LOG":"Record 0"}', u'{"LOG":"Record 1"}', u'{"LOG":"Record 2"}', u'{"LOG":"Record 3"}', u'{"LOG":"Record 4"}']
I ran it again for output2 and the identical output was shown.
Option 2: Using AWS Lambda
If you are fanning-out to many streams, a more efficient method might be to create an AWS Lambda function:
You could even have the Lambda function self-discover the output streams based on a naming convention (eg any stream named app-output-*).
If you love us? You can donate to us via Paypal or buy me a coffee so we can maintain and grow! Thank you!
Donate Us With

