I'm trying to figure out how non-destructive manipulation of large collections is implemented in functional programming, ie. how it is possible to alter or remove single elements without having to create a completely new collection where all elements, even the unmodified ones, will be duplicated in memory. (Even if the original collection would be garbage-collected, I'd expect the memory footprint and general performance of such a collection to be awful.)
Using F#, I came up with a function insert that splits a list into two pieces and introduces a new element in-between, seemingly without cloning all unchanged elements:
// return a list without its first n elements:
// (helper function)
let rec skip list n =
if n = 0 then
list
else
match list with
| [] -> []
| x::xs -> skip xs (n-1)
// return only the first n elements of a list:
// (helper function)
let rec take list n =
if n = 0 then
[]
else
match list with
| [] -> []
| x::xs -> x::(take xs (n-1))
// insert a value into a list at the specified zero-based position:
let insert list position value =
(take list position) @ [value] @ (skip list position)
I then checked whether objects from an original list are "recycled" in new lists by using .NET's Object.ReferenceEquals:
open System
let (===) x y =
Object.ReferenceEquals(x, y)
let x = Some(42)
let L = [Some(0); x; Some(43)]
let M = Some(1) |> insert L 1
The following three expressions all evaluate to true, indicating that the value referred to by x is re-used both in lists L and M, ie. that there is only 1 copy of this value in memory:
L.[1] === x
M.[2] === x
L.[1] === M.[2]
Do functional programming languages generally re-use values instead of cloning them to a new memory location, or was I just lucky with F#'s behaviour? Assuming the former, is this how reasonably memory-efficient editing of collections can be implemented in functional programming?
(Btw.: I know about Chris Okasaki's book Purely functional data structures, but haven't yet had the time to read it thoroughly.)
Functional programming languages are typically less efficient in their use of CPU and memory than imperative languages such as C and Pascal. This is related to the fact that some mutable data structures like arrays have a very straightforward implementation using present hardware.
Typically tuples, lists, and partially-evaluated functions are very common data structures in functional programming languages.
Functional Programming is used in situations where we have to perform lots of different operations on the same set of data. Lisp is used for artificial intelligence applications like Machine learning, language processing, Modeling of speech and vision, etc.
I'm trying to figure out how non-destructive manipulation of large collections is implemented in functional programming, ie. how it is possible to alter or remove single elements without having to create a completely new collection where all elements, even the unmodified ones, will be duplicated in memory.
This page has a few descriptions and implementations of data structures in F#. Most of them come from Okasaki's Purely Functional Data Structures, although the AVL tree is my own implementation since it wasn't present in the book.
Now, since you asked, about reusing unmodified nodes, let's take a simple binary tree:
type 'a tree =
| Node of 'a tree * 'a * 'a tree
| Nil
let rec insert v = function
| Node(l, x, r) as node ->
if v < x then Node(insert v l, x, r) // reuses x and r
elif v > x then Node(l, x, insert v r) // reuses x and l
else node
| Nil -> Node(Nil, v, Nil)
Note that we re-use some of our nodes. Let's say we start with this tree:
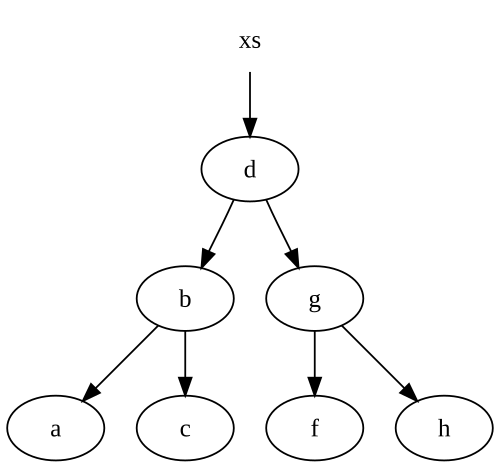
When we insert an e into the the tree, we get a brand new tree, with some of the nodes pointing back at our original tree:

If we don't have a reference to the xs tree above, then .NET will garbage collect any nodes without live references, specifically thed, g and f nodes.
Notice that we've only modified nodes along the path of our inserted node. This is pretty typical in most immutable data structures, including lists. So, the number of nodes we create is exactly equal to the number of nodes we need to traverse in order to insert into our data structure.
Do functional programming languages generally re-use values instead of cloning them to a new memory location, or was I just lucky with F#'s behaviour? Assuming the former, is this how reasonably memory-efficient editing of collections can be implemented in functional programming?
Yes.
Lists, however, aren't a very good data structure, since most non-trivial operations on them require O(n) time.
Balanced binary trees support O(log n) inserts, meaning we create O(log n) copies on every insert. Since log2(10^15) is ~= 50, the overhead is very very tiny for these particular data structures. Even if you keep around every copy of every object after inserts/deletes, your memory usage will increase at a rate of O(n log n) -- very reasonable, in my opinion.
How it is possible to alter or remove single elements without having to create a completely new collection where all elements, even the unmodified ones, will be duplicated in memory.
This works because no matter what kind of collection, the pointers to the elements are stored separately from the elements themselves. (Exception: some compilers will optimize some of the time, but they know what they are doing.) So for example, you can have two lists that differ only in the first element and share tails:
let shared = ["two", "three", "four"]
let l = "one" :: shared
let l' = "1a" :: shared
These two lists have the shared part in common and their first elements different. What's less obvious is that each list also begins with a unique pair, often called a "cons cell":
List l begins with a pair containing a pointer to "one" and a pointer to the shared tail.
List l' begins with a pair containing a pointer to "1a" and a pointer to the shared tail.
If we had only declared l and wanted to alter or remove the first element to get l', we'd do this:
let l' = match l with
| _ :: rest -> "1a" :: rest
| [] -> raise (Failure "cannot alter 1st elem of empty list")
There is constant cost:
Split l into its head and tail by examining the cons cell.
Allocate a new cons cell pointing to "1a" and the tail.
The new cons cell becomes the value of list l'.
If you're making point-like changes in the middle of a big collection, typically you'll be using some sort of balanced tree which uses logarithmic time and space. Less frequently you may use a more sophisticated data structure:
Gerard Huet's zipper can be defined for just about any tree-like data structure and can be used to traverse and make pointlike modifications at constant cost. Zippers are easy to understand.
Paterson and Hinze's finger trees offer very sophisticated representations of sequences, which among other tricks enable you to change elements in the middle efficiently—but they are hard to understand.
If you love us? You can donate to us via Paypal or buy me a coffee so we can maintain and grow! Thank you!
Donate Us With


