I write the following code in java and check the values stored in the variables. when I store 1.2 in a double variable 'y' it becomes 1.200000025443 something. Why it is not 1.200000000000 ?
public class DataTypes
{
static public void main(String[] args)
{
float a=1;
float b=1.2f;
float c=12e-1f;
float x=1.2f;
double y=x;
System.out.println("float a=1 shows a= "+a+"\nfloat b=1.2f shows b= "+b+"\nfloat c=12e-1f shows c= "+c+"\nfloat x=1.2f shows x= "+x+"\ndouble y=x shows y= "+y);
}
}
You can see the output here:
float a=1 shows a= 1.0 float b=1.2f shows b= 1.2 float c=12e-1f shows c= 1.2 float x=1.2f shows x= 1.2 double y=x shows y= 1.2000000476837158
This is a question of formatting above anything else.
Take a look at the Float.toString documentation (Float.toString is what's called to produce the decimal representations you see for the floats, and Double.toString for the double):
How many digits must be printed for the fractional part of m or a? There must be at least one digit to represent the fractional part, and beyond that as many, but only as many, more digits as are needed to uniquely distinguish the argument value from adjacent values of type
float. That is, suppose that x is the exact mathematical value represented by the decimal representation produced by this method for a finite nonzero argument f. Then f must be the float value nearest to x; or, if twofloatvalues are equally close to x, then f must be one of them and the least significant bit of the significand of f must be 0.
(emphasis mine)
The situation is the same for Double.toString. But, you need more digits to "uniquely distinguish the argument value from adjacent values of type double" than you do for float (recall that double is 64-bits while float is 32), that's why you're seeing the extra digits for double and not for float.
Note that anything that can be represented by float can also be represented by double, so you're not actually losing any precision in the conversion.
Of course, not all numbers can be exactly representable by float or double, which is why you see those seemingly random extra digits in the decimal representation in the first place. See "What Every Computer Scientist Should Know About Floating-Point Arithmetic".
The reason why there's such issue is because a computer works only in discrete mathematics, because the microprocessor can only represent internally full numbers, but no decimals. Because we cannot only work with such numbers, but also with decimals, to circumvent that, decades ago very smart engineers have invented the floating point representation, normalized as IEEE754.
The IEEE754 norm that defines how floats and doubles are interpreted in memory. Basically, unlike the int which represent an exact value, the floats and doubles are a calculation from:
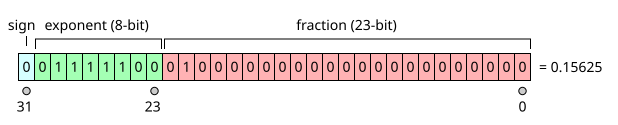
So the issue here is that when you're storing 1.2 as a double, you actually store a binary approximation to it:
00111111100110011001100110011010
which gives you the closest representation of 1.2 that can be stored using a binary fraction, but not exactly that fraction. In decimal fraction, 12*10^-1 gives an exact value, but as a binary fraction, it cannot give an exact value.
(cf http://www.h-schmidt.net/FloatConverter/IEEE754.html as I'm too lazy to do it myself)
when I store 1.2 in a double variable 'y' it becomes 1.200000025443 something
well actually in both the float and the double versions of y, the value actually is 1.2000000476837158, but because of the smaller mantissa of the float, the value represented is truncated before the approximation, making you believe it's an exact value, whereas in the memory it's not.
If you love us? You can donate to us via Paypal or buy me a coffee so we can maintain and grow! Thank you!
Donate Us With


