I've recently been thinking more about what kind of work computer hardware has to do to produce the things we expect.
Comparing text and color, it seems that both rely on combinations of 1's and 0's with 256 possible combinations per byte. ASCII may represent a letter such as (01100001) to be the letter 'A'. But then there may be a color R(01100001), G(01100001), B(01100001) representing some random color. Considering on a low level, the computer is just reading these collections of 1's and 0's, what needs to happen to ensure the computer renders the color R(01100001), G(01100001), B(01100001) and not the letter A three times on my screen?
 asked Feb 21 '13 20:02
asked Feb 21 '13 20:02
I'm not entirely sure this question is appropriate for Stack Overflow, but I'll go ahead and give a basic answer anyways. Though it's actually a very complicated question because depending on how deep you want to go into answering it I could write an entire book on computer architecture in order to do so.
So to keep it simple I'll just give you this: It's all a matter of context. First let's just tackle text:
When you open, say, a text editor the implicit assumption is the data to be displayed in it is textual in nature. The text to be displayed is some bytes in memory (possibly copied out of some bytes on disk). There's no magical internal context from the memory's point of view that these bytes are text. Instead, the source for text editor contains some commands that point to those bytes and say "these bytes represent 300 characters of text" for example. Then there's a complex sequence of steps involving library code all the way to hardware that handles mapping those bytes according to an encoding like ASCII (there are many other ways of encoding text) to characters, finding those characters in a font, writing that font to the screen, etc.
The point is it doesn't have to interpret those bytes as text. It just does because that's what a text editor does. You could hypothetically open it in an image program and tell it to interpret those same 300 bytes as a 10x10 array (or image) of RGB values.
As for colors the same logic applies. They're just bytes in memory. But when the code that's drawing something to the screen has decided what pixels it wants to write with what colors, it will pipe those bytes via a memory mapping to the video card which will then translate them to commands that are sent to the monitor (still in some binary format representing pixels and the colors, though the reality is a lot more complicated), and the monitor itself contains firmware that then handles the detail of mapping those colors to the physical pixels. The numbers that represent the colors themselves will at some point be converted to a specific current to each R/G/B channel to raise or lower its intensity.
That's all I have time for for now but it's a start.
Update: Just to illustrate my point, I took the text of Flatland from here. Which is just 216624 bytes of ASCII text (interpreted as such by your web browser based on context: the .txt extension helps, but the web server also provides a MIME type header informing the browser that it should be interpreted as plain text. Your browser might also analyze the bytes to determine that their pattern does look like that of plain text (and that there aren't an overwhelming number of bytes that don't represent ASCII characters). I appended a few spaces to the end of the text so that its length is 217083 which is 269 * 269 * 3 and then plotted it as a 269 x 269 RGB image:
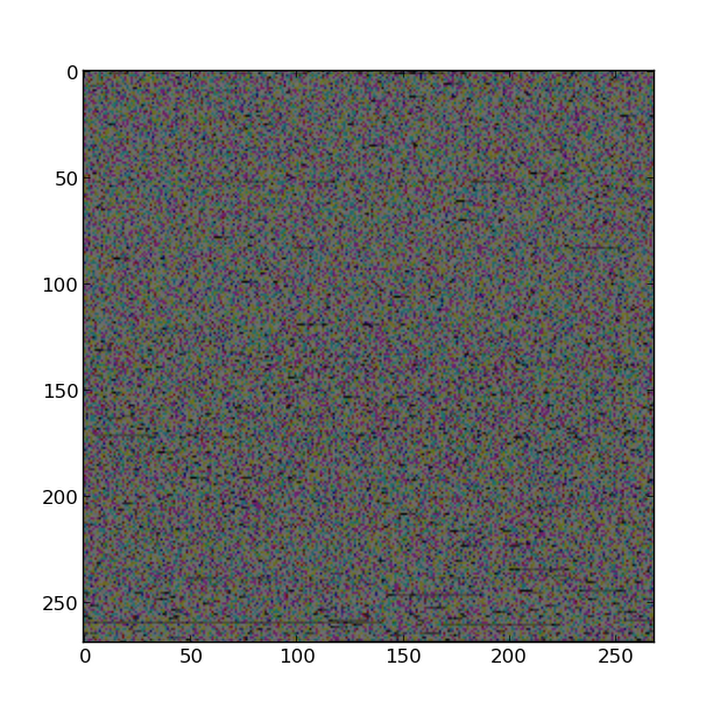
Not terribly interesting-looking. But the point is that I just took those same exact bytes and told the software, "okay, these are RGB values now". That's not to say that looking at plain text bytes as images can't be useful. For example, it can be a useful way to visualize an encryption algorithm. This shows an image that was encrypted with a pretty insecure algorithm--you can still get a very good sense of the patterns of bytes in the original unencrypted file. If it were text and not an image this would be no different, as text in a specific language like English also has known statistical patterns. A good encryption algorithm would look make the encrypted image look more like random noise.
Zero and one are just zero and one, nothing more. A byte is just a collection of 8 bit.
The meaning you assign to information depends on what you need at the moment, what "language" you use to interpret your information. 65 is either letter A in ASCII or number 65 if you're using it in, say, int a = 65 + 3.
At low level, different (thousands of) machine instructions are executed to ensure that your data is treated properly, depending for example on the type of file you're reading, its headers, which process requests the data, and so on. The different high-level functions you use to treat different information expand to very different machine code.
If you love us? You can donate to us via Paypal or buy me a coffee so we can maintain and grow! Thank you!
Donate Us With

