Having an HTML snippet like this:
<p>Lorem ipsum <mark>dolor</mark> sit amet. <mark>Lorem</mark> ipsum again
and <mark>dolor</mark></p>
I can select the <mark> elements using $("mark"). I want to get a list of strings representing the marked word and 5 characters on the left side and 5 characters in the right side and prefix and suffix the strings with [...].
For this example it would be:
[
"[...] psum dolor sit [...]",
"[...] met. Lorem ipsu [...]",
"[...] and dolor [...]",
]
Currently I'm something like this:
var $highlightMarks = $("mark");
var results = [];
for (var i = 0; i < $highlightMarks.length; ++i) {
var $c = $highlightMarks.eq(i);
var text = $c.parent().text().trim().replace(/\n/g, " ");
var indexStart = new RegExp($c.html(), "gim").exec(text).index;
text = "[...] " + text.substring(indexStart - 5, $c.html().length + indexStart + 5) + " [...]";
results.push(text);
}
alert(JSON.stringify(results))<script src="https://ajax.googleapis.com/ajax/libs/jquery/2.1.1/jquery.min.js"></script>
<p>Lorem ipsum <mark>dolor</mark> sit amet. <mark>Lorem</mark> ipsum again and <mark>dolor</mark>.</p>But this fails when two words are the same in the same paragraph (in this example: the dolor case).
Instead of showing psum dolor sit at the end of the array, it should be and dolor..
So, having a reference to the <mark> element, what's the correct way to get some text on the right side and some text on the left side?
textContents is all text contained by an element and all its children that are for formatting purposes only. innerText returns all text contained by an element and all its child elements.
To get the value of div content in jQuery, use the text() method. The text( ) method gets the combined text contents of all matched elements. This method works for both on XML and XHTML documents.
The JQuery html() and text() methods are two methods that you can use to get or set the contents of an HTML element. The difference between them is stated below: html() is used to return or change the html and text content of an element. text() can only return or change the text content of an element.
This is a two steps bulletproof implementation (counterexamples are welcomed) using only regex .
Its greatest virtue is to work independently from a tag container (just like the <p>...</p> to extract the text around marks).
var filter = /<(?![/]?mark)[^><]*>/gi;
var regex = /((?:(?!<[/]mark\s*>).){0,5})<mark\s*>([^<]*)<[/]mark\s*>(?=((?:(?!<mark\s*>).){0,5}))/ig;
var subst = "$1 $2 $3";
var tests = ['<p>Lorem ipsum mark> <MARK >dolor</MARK > < mark sitamet. <mark>Lorem</mark> ipsum again and <mark>dolor</mark>.</p>','<P style="margin: 0 15px 15px 0;">um <mark>dolor</mark> sit amet. <mark>Lorem</mark> ipsum again and <mark>dolor</mark>.</P>','<p>um <mark>dolor</mark> <span>sit</ span> <test amet. <mark>Lorem</mark> <b>i</b>psum again and <mark>dolor</mark>.</p>','<p style="margin: 0 15px 15px 0;" another_tag="123">Lorem ipsum <MARK >dolor</MARK > sit <mark>amet.</mark><mark>Lorem</mark> ipsum again and <mark>dolor</mark>.</P>'];
while(t = tests.pop()) {
document.write('<b>INPUT</b> <xmp>' + t + '</xmp>');
var t = t.replace(filter,'');
document.write('<b>Filtered:</b> <xmp>' + t + '</xmp>');
while ((r = regex.exec(t)) != null) {
pre = r[1]; marked = r[2]; post = r[3];
document.write('<b>Match:</b> "' + pre + ' <mark>' + marked + '</mark> ' + post + '"<hr/>');
}
}Filter out every tag that is not a <mark> or a </mark> tag (case insensitive and space relaxed according to what is accepted by chrome and firefox: the regex does accept also the variations <mark > or </mark > as valid tags but not < mark> or </ mark>:
/<(?![/]?mark)[^><]*>/gi
Regex 101 Demo
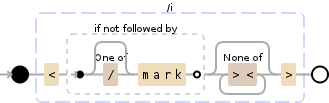
NOTE: this filter handles the single chars '<' and '>' correctly (with or without text after/before them).
This behaves differently from a browser regard the opening tag char <: anything after <someText till the next valid tag will be removed (breaking valid html tags). I prefer do not do this way and treat an opening not closed '<' as a simple char.
e.g.: Some text <notAtag other text <mark>marked</mark>. chrome or firefox will output Some text marked (with marked actually not marked cause the <mark> tag is been filtered out together with <notAtag other text).
Select the marked text and its context (till 5 characters)
/((?:(?!<[/]mark\s*>).){0,5}) #* 0 to 5 chars that not belongs to '<mark\s*>'
# the round brackets save them in group $1
<mark\s*> #* literal string '<mark' followed by
# 0 or more whitespace chars then literal '>'
([^<]*) #* 0 or more chars that is not '<'
# the round brackets save them in group $2
<[/]mark\s*> #* literal string '</mark' followed by
# 0 or more whitespace chars then literal '>'
(?=((?:(?!<mark\s*>).){0,5})) #* 0 to 5 chars that not belongs to '</mark\s*>'
# lookahead (?=...) used to not consume them
# round brackets save them in $3
/ig #* i: Case-insensitive, g: global search
Regex 101 Demo

NOTE: The regex is smart enough to select 5 chars both from the previous and the next <mark> if is the case (e.g. </mark>12345<mark>, 12345 will be both post context of the closing tag and the pre context of the opening tag).
In addiction the context selection avoid to select over <mark> tags so :
...</mark><mark>... tags nothing is selected as post/pre context;</mark>123<mark>: only 123 is selected as post/pre context.If you love us? You can donate to us via Paypal or buy me a coffee so we can maintain and grow! Thank you!
Donate Us With

