How do I write a regex that gets title and, if available, year from filenames? See examples below.
This solution works for php but im having problem translating it into javascript Seprate movie name and year from moviefile name
The.Great.Gatsby.2013.BluRay.1080p.DTS.x264-CHD.mkv
The Forbidden Girl 2013 BRRIP Xvid AC3-BHRG.avi
Pain.&.Gain.2013.720p.BluRay.DD5.1.x264-HiDt.mkv
Se7en.avi
Se7en.(1995).avi
How to train your dragon 2.mkv
10,000BC (2010).1080p.avi
The solution provided below works for all the test cases you provided (and some extra as the titlelize, see the code below) and is intended to be customizable.
Long story short, try the snippet below:
// Live Test
var input = document.getElementById('input');
var output = document.getElementById('output');
input.oninput = function() { output.textContent = extractData(input.value); }
// Samples
var tests = ['The.Great.Gatsby.2013.BluRay.1080p.DTS.x264-CHD.mkv', 'The Forbidden Girl 2013 BRRIP Xvid AC3-BHRG.avi', 'Pain.&.Gain.2013.720p.BluRay.DD5.1.x264-HiDt.mkv', 'Se7en.(1995).avi', 'How to train your dragon 2.mkv', '10,000BC (2010).1080p.avi', 'The.Great.Gatsby.BluRay.1080p.DTS.x264-CHD.mkv', 'Se7en.avi', '2001 A Space Odyssey.BluRay.1080p.DTS.x264-CHD.mkv','Sand.Castle.2017.FRENCH.1080.WEBRip.AAC2.0-NEWCiNE-WwW.Zone-Telechargement.Ws.mkv'];
while (t = tests.pop()) {
document.getElementById('list').innerHTML += '<b>INPUT</b>: "' + t + '"<br>';
document.getElementById('list').innerHTML += extractData(t,true) + '<hr>';
}
function titlelize(title) {
return title.replace(/(^|[. ]+)(\S)/g, function(all, pre, c) { return ((pre) ? ' ' : '') + c.toUpperCase(); });
};
function extractData(it, html) {
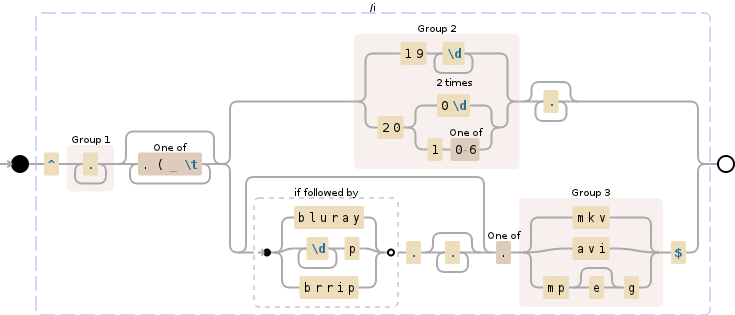
var regex = /^(.+?)[.( \t]*(?:(19\d{2}|20(?:0\d|1[0-9])).*|(?:(?=bluray|\d+p|brrip|webrip)..*)?[.](mkv|avi|mpe?g|mp4)$)/i;
var out = '↳ ';
if ( m = regex.exec(it) ) {
title = titlelize(m[1]) || '-'; year = m[2] || '-';
out += '<font color="green"><b>Title</b>: "' + title +
'"  <b>Year</b>: "' + year + '"</font>';
} else {
out += '<font color="red">No match</font>';
}
//the replace is an hack to remove html in live input text
return (html) ? out : out.replace(/<[^>]+>|&[^;]+;/g,'');
}<mark><b>Paste and Try!</b></mark> ⇒ <input id="input" type="text" size="70" />
<br>↳ <span id="output" style="line-height:40px;">No Match</span>
<hr>
<div id="list"></div>Description
Assuming the title is structured roughly as this:
Title* || [ Year* ] || [ Codec ] Extension
The fields enclosed in square brackets are optional (e.g [field1])
* : field saved
The key is to match everything as title till the last valid year found (valid years: 1900-2016) or till the file extension (structured as a dot plus 3 letters, simple to change if needed).
Exceptions: in the case where a film does not contain a valid year at all the section starting with (case insensitive) bluray or [0-9]+p (e.g. 720p, 1080p) or brrip is stripped from the title section.
Regex Breakout Regex101 Demo
/^
(.+?) # Save title into group $1
[.( \t]* # Remove some separators
(?: # Non capturing group
(19\d{2}|20(?:0\d|1[0-6])).* # Save years (1900-2016) in $2
| # OR
(?:(?=bluray|\d+p|brrip)..*)? # Match string starting with bluray,brrip,720p...
[.](mkv|avi|mpe?g)$) # Match extension (.mkv,.avi.,mpeg) add your own
/i # make the regex case insensitive
Regex Customization
The list of exceptions and extensions can be easily filled with new values little by little during tests when/if needed (as file extension, e.g. to add .wmv and .flv add them to the (mkv|avi|mpe?g|wmv|flv) section of the regex) or to make the section generic replace it with [.]\w{3,4}$.
If you love us? You can donate to us via Paypal or buy me a coffee so we can maintain and grow! Thank you!
Donate Us With

