I have a program that needs to repeatedly compute the approximate percentile (order statistic) of a dataset in order to remove outliers before further processing. I'm currently doing so by sorting the array of values and picking the appropriate element; this is doable, but it's a noticable blip on the profiles despite being a fairly minor part of the program.
More info:
Although this is all done in a loop, the data is (slightly) different every time, so it's not easy to reuse a datastructure as was done for this question.
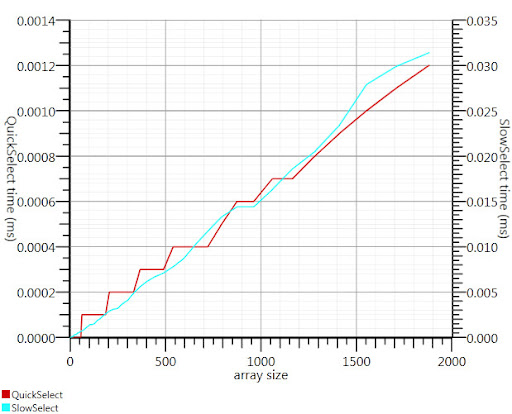
Using the wikipedia selection algorithm as suggested by Gronim reduced this part of the run-time by about a factor 20.
Since I couldn't find a C# implementation, here's what I came up with. It's faster even for small inputs than Array.Sort; and at 1000 elements it's 25 times faster.
public static double QuickSelect(double[] list, int k) {
return QuickSelect(list, k, 0, list.Length);
}
public static double QuickSelect(double[] list, int k, int startI, int endI) {
while (true) {
// Assume startI <= k < endI
int pivotI = (startI + endI) / 2; //arbitrary, but good if sorted
int splitI = partition(list, startI, endI, pivotI);
if (k < splitI)
endI = splitI;
else if (k > splitI)
startI = splitI + 1;
else //if (k == splitI)
return list[k];
}
//when this returns, all elements of list[i] <= list[k] iif i <= k
}
static int partition(double[] list, int startI, int endI, int pivotI) {
double pivotValue = list[pivotI];
list[pivotI] = list[startI];
list[startI] = pivotValue;
int storeI = startI + 1;//no need to store @ pivot item, it's good already.
//Invariant: startI < storeI <= endI
while (storeI < endI && list[storeI] <= pivotValue) ++storeI; //fast if sorted
//now storeI == endI || list[storeI] > pivotValue
//so elem @storeI is either irrelevant or too large.
for (int i = storeI + 1; i < endI; ++i)
if (list[i] <= pivotValue) {
list.swap_elems(i, storeI);
++storeI;
}
int newPivotI = storeI - 1;
list[startI] = list[newPivotI];
list[newPivotI] = pivotValue;
//now [startI, newPivotI] are <= to pivotValue && list[newPivotI] == pivotValue.
return newPivotI;
}
static void swap_elems(this double[] list, int i, int j) {
double tmp = list[i];
list[i] = list[j];
list[j] = tmp;
}
Thanks, Gronim, for pointing me in the right direction!
The histogram solution from Henrik will work. You can also use a selection algorithm to efficiently find the k largest or smallest elements in an array of n elements in O(n). To use this for the 95th percentile set k=0.05n and find the k largest elements.
Reference:
http://en.wikipedia.org/wiki/Selection_algorithm#Selecting_k_smallest_or_largest_elements
According to its creator a SoftHeap can be used to:
compute exact or approximate medians and percentiles optimally. It is also useful for approximate sorting...
If you love us? You can donate to us via Paypal or buy me a coffee so we can maintain and grow! Thank you!
Donate Us With


