So I wanted to test the speed of C++ vs Matlab for solving a linear system of equations. For this purpose I create a random system and measure the time required to solve it using Eigen on Visual Studio:
#include <Eigen/Core>
#include <Eigen/Dense>
#include <chrono>
using namespace Eigen;
using namespace std;
int main()
{
chrono::steady_clock sc; // create an object of `steady_clock` class
int n;
n = 5000;
MatrixXf m = MatrixXf::Random(n, n);
VectorXf b = VectorXf::Random(n);
auto start = sc.now(); // start timer
VectorXf x = m.lu().solve(b);
auto end = sc.now();
// measure time span between start & end
auto time_span = static_cast<chrono::duration<double>>(end - start);
cout << "Operation took: " << time_span.count() << " seconds !!!";
}
Solving this 5000 x 5000 system takes 6.4 seconds on average. Doing the same in Matlab takes 0.9 seconds. The matlab code is as follows:
a = rand(5000); b = rand(5000,1);
tic
x = a\b;
toc
According to this flowchart of the backslash operator:
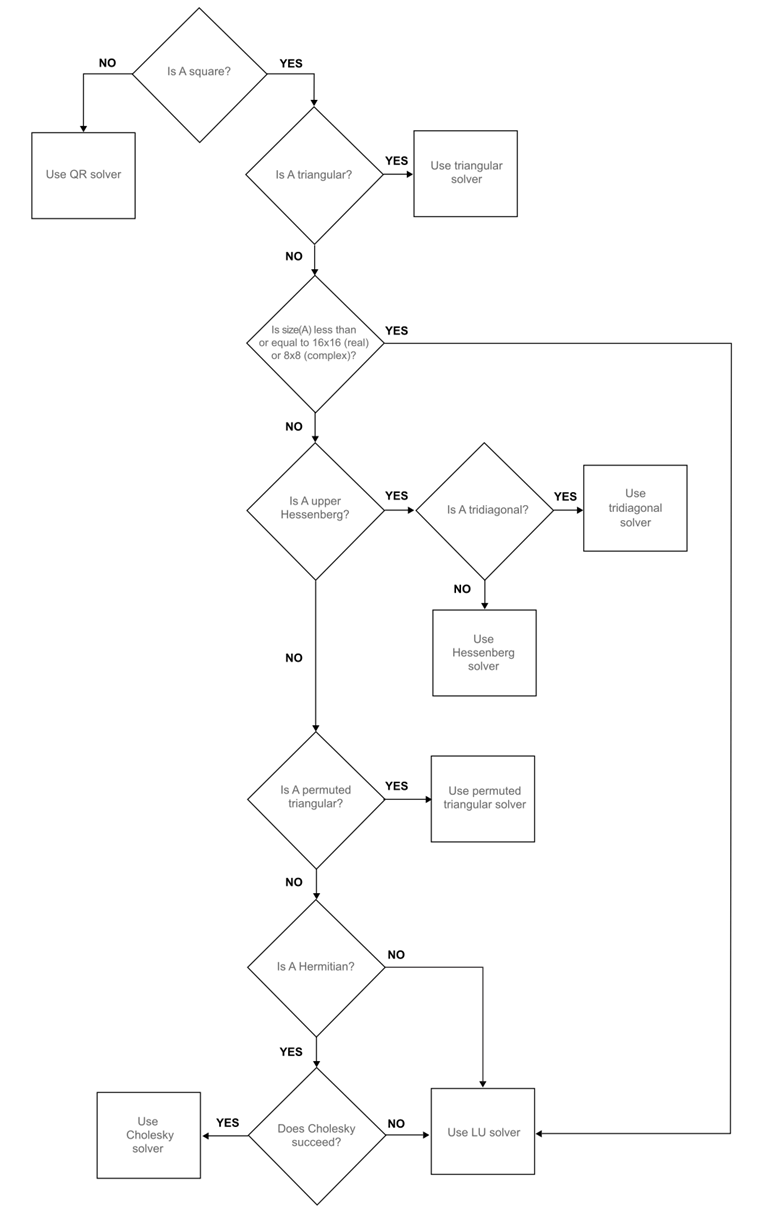
given that a random matrix is not triangular, permuted triangular, hermitian or upper heisenberg, the backslash operator in Matlab uses a LU solver, which I believe is the same solver that I'm using on the C++ code, that is, lu().solve
Probably there is something that I'm missing, because I thought C++ was faster.
In: Matrix Methods.
There are three ways to solve systems of linear equations in two variables: graphing. substitution method. elimination method.
First of all, for this kind of operations Eigen is very unlikely to beat MatLab because the later will directly call Intel's MKL which is heavily optimized and multi-threaded. Note that you can also configure Eigen to fallback to MKL, see how. If you do so, you'll end up with similar performance.
Nonetheless, 6.4s is way to much. The Eigen's documentation reports 0.7s for factorizing a 4k x 4k matrix. Running your example on my computer (Haswell laptop @2.6GHz) I got 1.6s (clang 7, -O3 -march=native), and 1s with multithreading enabled (-fopenmp). So make sure you enable all your CPU's feature (AVX, FMA) and openmp. With OpenMP you might need to explicitly reduce the number of openmp threads to the number of physical cores.
If you love us? You can donate to us via Paypal or buy me a coffee so we can maintain and grow! Thank you!
Donate Us With